“A hyperparameter is a parameter that is set before the learning process begins. These parameters are tunable and can directly affect how well a model trains.”
root@root:/opt/gym/examples/agents# python3 random_agent.py INFO: Making new env: CartPole-v0 INFO: Creating monitor directory /tmp/random-agent-results INFO: Starting new video recorder writing to /tmp/random-agent-results/openaigym.video.0.4726.video000000.mp4 INFO: Starting new video recorder writing to /tmp/random-agent-results/openaigym.video.0.4726.video000001.mp4 INFO: Starting new video recorder writing to /tmp/random-agent-results/openaigym.video.0.4726.video000008.mp4 INFO: Starting new video recorder writing to /tmp/random-agent-results/openaigym.video.0.4726.video000027.mp4 INFO: Starting new video recorder writing to /tmp/random-agent-results/openaigym.video.0.4726.video000064.mp4 INFO: Finished writing results. You can upload them to the scoreboard via gym.upload(‘/tmp/random-agent-results’) root@chrx:/opt/gym/examples/agents#
Last week, I wrote an article about NEAT (NeuroEvolution of Augmenting Topologies) and we discussed a lot of the cool things that surrounded the algorithm. We also briefly touched upon how this older algorithm might even impact how we approach network building today, alluding to the fact that neural networks need not be built entirely by hand.
Today, we are going to dive into a different approach to neuroevolution, an extension of NEAT called HyperNEAT. NEAT, as you might remember, had a direct encoding for its network structure. This was so that networks could be more intuitively evolved, node by node and connection by connection. HyperNEAT drops this idea because in order to evolve a network like the brain (with billions of neurons), one would need a much faster way of evolving that structure.
HyperNEAT is a much more conceptually complex algorithm (in my opinion, at least) and even I am working on understanding the nuts and bolts of how it all works. Today, we will take a look under the hood and explore some of the components of this algorithm so that we might better understand what makes it so powerful and reason about future extensions in this age of deep learning.
HyperNEAT
Motivation
Before diving into the paper and algorithm, I think it’s worth exploring a bit more the motivation behind HyperNEAT.
The full name of the paper is “A Hypercube-Based Indirect Encoding for Evolving Large-Scale Neural Networks”, which is quite the mouthful! But already, we can see two of the major points. It’s a hypercube-based indirect encoding. We’ll get into the hypercube part later, but already we know that it’s a move from direct encodings to indirect encodings (see my last blog on NEAT for a more detailed description of some of the differences between the two). Furthermore, we get the major reasoning behind it as well: For evolving big neural nets!
More than that, the creators of this algorithm highlight that if one were to look at the brain, they see a “network” with billions of nodes and trillions of connections. They see a network that uses repetition of structure, reusing a mapping of the same gene to generate the same physical structure multiple times. They also highlight that the human brain is constructed in a way so as to exploit physical properties of the world: symmetry (have mirrors of structures, two eyes for input for example) and locality (where nodes are in the structure influences their connections and functions).
Contrast this what we know about neural networks, either built through an evolution procedure or constructed by hand and trained. Do any of these properties hold? Sure, if we force the network to have symmetry and locality, maybe… However, even then, take a dense, feed-forward network where all nodes in one layer are connected to all nodes in the next! And when looking at the networks constructed by the vanilla NEAT algorithm? They tend to be disorganized, sporadic, and not exhibit any of these nice regularities.
Enter in HyperNEAT! Utilizing an indirect encoding through something called connective Compositional Pattern Producing Networks (CPPNs), HyperNEAT attempts to exploit geometric properties to produce very large neural networks with these nice features that we might like to see in our evolved networks.
What’s a Compositional Pattern Producing Network?
In the previous post, we discussed encodings and today we’ll dive deeper into the indirect encoding used for HyperNEAT. Now, indirect encodings are a lot more common than you might think. In fact, you have one inside yourself!
DNA is an indirect encoding because the phenotypic results (what we actually see) are orders of magnitude larger than the genotypic content (the genes in the DNA). If you look at a human genome, we’ll say it has about 30,000 genes coding for approximately 3 billion amino acids. Well, the brain has 3 trillion connections. Obviously, there is something indirect going on here!
Something borrowed from the ideas of biology is an encoding scheme called developmental encoding. This is the idea that all genes should be able to be reused at any point in time during the developmental process and at any location within the individual. Compositional Pattern Producing Networks (CPPNs) are an abstraction of this concept that have been show to be able to create patterns for repeating structures in Cartesian space. See some structures that were produced with CPPNs here:
Pure CPPNs
A phenotype can be described as a function of n dimensions, where n is the number of phenotypic traits. What we see is the result of some transformation from genetic encoding to the exhibited traits. By composing simple functions, complex patterns can actually be easily represented. Things like symmetry, repetition, asymmetry, and variation all easily fall out of an encoding structure like this depending on the types of networks that are produced.
We’ll go a little bit deeper into the specifics of how CPPNs are specifically used in this context, but hopefully this gives you the general feel for why and how they are important in the context of indirect encodings.
Tie In to NEAT
In HyperNEAT, a bunch of familiar properties reappear for the original NEAT paper. Things like complexification over time are important (we’ll start with simple and evolve complexity if and when it’s needed). Historical markings will be used so that we can properly line up encodings for any sort of crossover. Uniform starting populations will also be used so that there’s no wildcard, incompatible networks from the start.
The major difference in how NEAT is used in this paper and the previous? Instead of using the NEAT algorithm to evolve neural networks directly, HyperNEAT uses NEAT to evolve CPPNs. This means that more “activation” functions are used for CPPNs since things like Gaussians give rise to symmetry and trigonometric functions help with repetition of structure.
The Algorithm
So now that we’ve talked about what a CPPN is and that we use the NEAT algorithm to evolve and adjust them, it begs the question of how are these actually used in the overall HyperNEAT context?
First, we need to introduce the concept of a substrate. In the scope of HyperNEAT, a substrate is simply a geometric ordering of nodes. The simplest example could be a plane or a grid, where each discrete (x, y) point is a node. A connective CPPN will actually take two of these points and compute weight between these two nodes. We could think of that as the following equation:
CPPN(x1, y1, x2, y2) = w
Where CPPN is an evolved CPPN, like that of what we’ve discussed in previous sections. We can see that in doing this, every single node will actually have some sort of weight connection between them (even allowing for recurrent connections). Connections can be positive or negative, and a minimum weight magnitude can also be defined so that any outputs below that threshold will result in no connection.
The geometric layout of nodes must be specified prior to the evolution of any CPPN. As a result, as the CPPN is evolved, the actually connection weights and network topology will result in a pattern that is geometric (all inputs are based on the positions of nodes).
In the case where the nodes are arranged on some sort of 2 dimensional plane or grid, the CPPN is a function of four dimensions and thus we can say it is being evolved on a four dimensional hypercube. This is where we get the name of the paper!
Regularities in the Produced Patterns
All regularities that we’ve mentioned before can easily fall out of an encoding like this. Symmetry can occur by using symmetric functions over something like x1 and x2. This can be a function like a Gaussian function. Imperfect symmetry can occur when symmetry is used over things like both x and y, but only with respect to one axis.
Repetition also falls out, like we’ve mentioned before, with periodic functions such as sine, cosine, etc. And like with symmetry, variation against repetition can be introduced by inducing a periodic function over a non-repeating aspect of the substrate. Thus all four major regularities that were aimed for are able to develop from this encoding.
Substrate Configuration
You may have guessed from the above that the configuration of the substrate is critical. And that makes a lot of sense. In biology, the structure of something is tied to its functionality. Therefore, in our own evolution schema, the structure of our nodes are tightly linked to the functionality and performance that may be seen on a particular task.
Here, we can see a couple of substrate configurations specifically outlined in the original paper:
I think it’s very important to look at the configuration that is a three dimensional cube and note how it simply adjusts our CPPN equation from four dimensional to six dimensional:
CPPN(x1, y1, z1, x2, y2, z2) = w
Also, the grid can be extended to the sandwich configuration by only allowing for nodes on one half to connect to the other half. This can be seen easily as an input/output configuration! The authors of the paper actually use this configuration to take in visual activation on the input half and use it to activate certain nodes on the output half.
The circular layout is also interesting, as geometry need not be a grid for a configuration. A radial geometry can be used instead, allowing for interesting behavioral properties to spawn out of the unique geometry that a circle can represent.
Input and Output Layout
Inputs and outputs are laid out prior to the evolution of CPPNs. However, unlike a traditional neural network, our HyperNEAT algorithm is made aware of the geometry of the inputs and outputs and can learn to exploit and embrace the regularities of it. Locality and repetition of inputs and outputs can be easily exploited through this extra information that HyperNEAT receives.
Substrate Resolution
Another powerful and unique property of HyperNEAT is the ability to scale the resolution of a substrate up and down. What does that mean? Well, let’s say you evolve a HyperNEAT network based on images of a certain size. The underlying geometry that was exploited to perform well at that size results in the same pattern when scaled to a new size. Except, no extra training is needed. It simply scales to another size!
Summarization of the Algorithm
I think with all that information about how this algorithm works, it’s worth summarizing the steps of it.
1. Chose a substrate configuration (the layout of nodes and where input/output is located)
2. Create a uniform, minimal initial population of connective CPPNs
3. Repeat until solution:
4. For each CPPN
(a) Generate connections for the neural network using the CPPN
(b) Evaluate the performance of the neural network
5. Reproduce CPPNs using NEAT algorithm
Conclusion
And there we have it! That’s the HyperNEAT algorithm. I encourage you to take a look at the paper if you wish to explore more of the details or wish to look at the performance on some of the experiments they did with the algorithm (I particularly enjoy their food gathering robot experiment).
What are the implications for the future? That’s something I’ve been thinking about recently as well. Is there a tie-in from HyperNEAT to training traditional deep networks today? Is this a better way to train deep networks? There’s another paper of Evolvable Substrate HyperNEAT where the actual substrates are evolved as well, a paper I wish to explore in the future! But is there something hidden in that paper that bridges the gap between HyperNEAT and deep neural networks? Only time will tell and only we can answer that question!
Hopefully, this article was helpful! If I missed anything or if you have questions, let me know. I’m still learning and exploring a lot of this myself so I’d be more than happy to have a conversation about it on here or on Twitter.
And if you want to read more of what I’ve written, maybe check out:
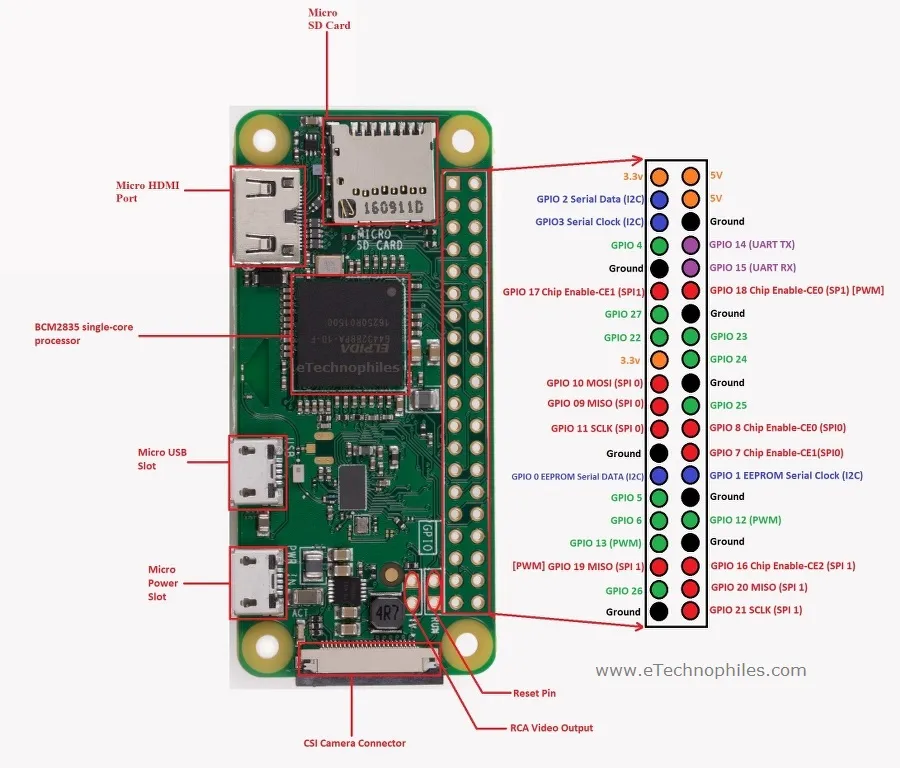
I started up a raspberry pi with raspbian installed on it. (I used balena’s etcher to flash an sd card): the light version, basically just Debian OS for rpi: https://www.raspberrypi.org/downloads/raspbian/
Ok but how do we power servos? We can’t run it off the RPi’s 5V 2A. Oh duh, there’s that big DC socket connected to the PCA9685
There is something to be said for running the robot on an Arduino. You get something robotic. You upload someone’s hexapod spider code, and it does a little dance. You can control it remotely. It can interact with sensors.
Arduinos are dirt cheap. So I bet we could have tiny neural networks running in arduinos… shit, do we already have them? Let’s see… ok wow there is like a whole thing. https://blog.arduino.cc/2019/10/15/get-started-with-machine-learning-on-arduino/ ok but 2K of RAM is not much. You would need to be a real demo scene junky to use a 2KB NN, but yeah, you could do something crudely intelligent with it.
Robots on ESP32s are definitely a thing. But ok no, Raspberry Pi for real robot. We need Linux for this.
Ok so I need to wire this up. But I also need a chassis for the robot.
open-endedness is a property of fitness landscapes, says a guy.
Banzhaf identified three different types of novelty:
(1) novelty within a model (variation), (2) novelty that changes the model (innovation), and (3) novelty that changes the meta-model5 (emergence).
NEAT and HyperNEAT
Instead of using the NEAT algorithm to evolve neural networks directly, HyperNEAT uses NEAT to evolve CPPNs. This means that more “activation” functions are used for CPPNs since things like Gaussians give rise to symmetry and trigonometric functions help with repetition of structure.
According to some blog bit: https://gitmemory.com/issue/bulletphysics/bullet3/2118/468943185 there might be an issue: “The problem with this demo is the following: It can not optimize since the robots are not properly restored. Their physical settings are not properly restored and thus their performance varies. I think it should only serve as a bullet example that does some simulation. If you can improve it to restore the physics correctly, that is fine, but this might be hard to do if you are new to bullet. It would be best to reimplement it in pybullet, because it features deterministic restoring of robots.”
So will have to keep that in mind.
So starting in the NN3DWalkersTimeWarp code, we quickly run into ERP and CFM http://www.ode.org/ode-latest-userguide.html#sec_3_7_0 – These are error reduction parameter and constraint force mixing and help fix errors caused by joints that aren’t set up perfectly.
The code also loads a number of Constraint Solvers:
btDefaultCollisionConfiguration in a btCollisionDispatcher
a default btDbvtBroadphase (a sweeping style collision detection)
and whichever solver is being used.
The Dynamics world is initiated as a btDiscreteDynamicsWorld
There’s timeWarpSimulation which we override, and the stepSimulation which is in a loop called the ‘canonical game loop’. It updates any variables changed by the UI parameters, then calls our code, and then updates and time variables that need refreshing, and gives you a chance to update some graphics. It gets to the end of the loop, checks the time, to decide whether to render the graphics, or to do the loop again.
That’s sufficient for now, to move on with the CPP file code.
Another interesting project I saw now, using OGRE, which is some other physics engine, I think, is https://github.com/benelot/minemonics – has some evolved life too.
But we are evolving something that looks more like these creepy rainbow spider bombs, that ‘we made’ in MotorDemo.cpp.
These above are the variables for the walker, which is similar to the MotorDemo critter. The code has been upgraded here and there since MotorDemo.cpp. It’s pretty great that people share their hard work so that we can just waltz on in and hack a quick robot together. This guy https://github.com/erwincoumans founded the Bullet project, and now works for Google Brain. (on Google Brain?)
So these are some of the public methods for the WalkersExample
We want to evolve behaviours based on stimulus, and the NNWalkers even have m_touchSensors, which we’ll have a look at later, to wee what they let us do.
Interlude: http://news.mit.edu/2015/algorithm-helps-robots-handle-uncertainty-0602 here says the following, and also has a video with sick drone rock music. This is a good part to remember, that either the robot is pausing, evaluating, pausing, evaluating, to accomplish the behaviours using ‘online’ feedback and offline policy processing.
There’s an offline planning phase where the agents can figure out a policy together that says, ‘If I take this set of actions, given that I’ve made these observations during online execution, and you take these other sets of actions, given that you’ve made these observations, then we can all agree that the whole set of actions that we take is pretty close to optimal,’” says Shayegan Omidshafiei, an MIT graduate student in aeronautics and astronautics and first author on the new paper. “There’s no point during the online phase where the agents stop and say, ‘This is my belief. This is your belief. Let’s come up with a consensus on the best overall belief and replan.’ Each one just does its own thing.
bool fitnessComparator(const NNWalker* a, const NNWalker* b)
{
return a->getFitness() > b->getFitness(); // sort walkers descending
}
So we are maximising fitness, and this is the Comparator function
The ratingEvaluations function orders by fitness, and prints the square root of the best performing individual’s distance fitness. Then we iterate through the walkers, update the time series canvas tick (next generation). Zero the times, and counters.
void NN3DWalkersExample::rateEvaluations()
{
m_walkersInPopulation.quickSort(fitnessComparator); // Sort walkers by fitness
b3Printf("Best performing walker: %f meters", btSqrt(m_walkersInPopulation[0]->getDistanceFitness()));
for (int i = 0; i < NUM_WALKERS; i++)
{
m_timeSeriesCanvas->insertDataAtCurrentTime(btSqrt(m_walkersInPopulation[i]->getDistanceFitness()), 0, true);
}
m_timeSeriesCanvas->nextTick();
for (int i = 0; i < NUM_WALKERS; i++)
{
m_walkersInPopulation[i]->setEvaluationTime(0);
}
m_nextReaped = 0;
}
The reap function uses the REAP_QTY (0.3) to iterate backwards through the worst 30%, set them to reaped.
void NN3DWalkersExample::reap()
{
int reaped = 0;
for (int i = NUM_WALKERS - 1; i >= (NUM_WALKERS - 1) * (1 - REAP_QTY); i--)
{ // reap a certain percentage
m_walkersInPopulation[i]->setReaped(true);
reaped++;
b3Printf("%i Walker(s) reaped.", reaped);
}
}
getRandomElite and getRandomNonElite use SOW_ELITE_QTY (set to 0.2). The functions return one in the first 20% and the last 80%.
The getNextReaped() function checks if we’ve reaped the REAP_QTY percentage yet. If not, increment counter and return the next reaped individual.
NNWalker* NN3DWalkersExample::getNextReaped()
{
if ((NUM_WALKERS - 1) - m_nextReaped >= (NUM_WALKERS - 1) * (1 - REAP_QTY))
{
m_nextReaped++;
}
if (m_walkersInPopulation[(NUM_WALKERS - 1) - m_nextReaped + 1]->isReaped())
{
return m_walkersInPopulation[(NUM_WALKERS - 1) - m_nextReaped + 1];
}
else
{
return NULL; // we asked for too many
}
}
Next is sow()…
SOW_CROSSOVER_QTY is 0.2, SOW_ELITE_PARTNER is 0.8. SOW_MUTATION_QTY is 0.5. MUTATION_RATE is 0.5. SOW_ELITE_QTY is 0.2. So we iterate over 20% of the population, increase sow count, get random elite mother, and 80% of the time, a random elite father (20% non-elite). Grab a reaped individual, and make it into a crossover of the parents.
Then mutations are performed on the population from 20% to 70%, passing in some scalar to the mutate().
Finally, the REAP_QTY – SOW_CROSSOVER_QTY is 10%, who are sown as randomized motor weight individuals.
Ok…
void NN3DWalkersExample::sow()
{
int sow = 0;
for (int i = 0; i < NUM_WALKERS * (SOW_CROSSOVER_QTY); i++)
{ // create number of new crossover creatures
sow++;
b3Printf("%i Walker(s) sown.", sow);
NNWalker* mother = getRandomElite(); // Get elite partner (mother)
NNWalker* father = (SOW_ELITE_PARTNER < rand() / RAND_MAX) ? getRandomElite() : getRandomNonElite(); //Get elite or random partner (father)
NNWalker* offspring = getNextReaped();
crossover(mother, father, offspring);
}
for (int i = NUM_WALKERS * SOW_ELITE_QTY; i < NUM_WALKERS * (SOW_ELITE_QTY + SOW_MUTATION_QTY); i++)
{ // create mutants
mutate(m_walkersInPopulation[i], btScalar(MUTATION_RATE / (NUM_WALKERS * SOW_MUTATION_QTY) * (i - NUM_WALKERS * SOW_ELITE_QTY)));
}
for (int i = 0; i < (NUM_WALKERS - 1) * (REAP_QTY - SOW_CROSSOVER_QTY); i++)
{
sow++;
b3Printf("%i Walker(s) sown.", sow);
NNWalker* reaped = getNextReaped();
reaped->setReaped(false);
reaped->randomizeSensoryMotorWeights();
}
}
Crossover goes through the joints, and sets half of the motor weights to the mom and half to the dad, randomly.
void NN3DWalkersExample::crossover(NNWalker* mother, NNWalker* father, NNWalker* child)
{
for (int i = 0; i < BODYPART_COUNT * JOINT_COUNT; i++)
{
btScalar random = ((double)rand() / (RAND_MAX));
if (random >= 0.5f)
{
child->getSensoryMotorWeights()[i] = mother->getSensoryMotorWeights()[i];
}
else
{
child->getSensoryMotorWeights()[i] = father->getSensoryMotorWeights()[i];
}
}
}
mutate() takes a mutation rate, and randomizes motor weights at that rate.
void NN3DWalkersExample::mutate(NNWalker* mutant, btScalar mutationRate)
{
for (int i = 0; i < BODYPART_COUNT * JOINT_COUNT; i++)
{
btScalar random = ((double)rand() / (RAND_MAX));
if (random >= mutationRate)
{
mutant->getSensoryMotorWeights()[i] = ((double)rand() / (RAND_MAX)) * 2.0f - 1.0f;
}
}
}