Good wiki page. When reading AI/ML articles and papers, pseudocode and math is often written using greek symbols. Like Σ (sigma) for summing. Like, θ (theta) is for polar coordinates, or to refer to the ‘policy’ of an agent. STEM students osmose the many meanings of the symbols over years of study.
When you learn Calculus, you first learn about differentiation, and Newton’s method, which is when you keep taking the derivative, and drawing a line. https://en.wikipedia.org/wiki/Newton’s_method
SGD is kinda like that but with a bit more statistics involved. Adam is using the second derivative too and keeping track of averages, etc., making it a bit more sophisticated than Newton’s method.
Finding where a derivative is zero, is how you find local optima and minima, and so SGD can lead you towards solutions. (Evolutionary algorithms offer a less direct path towards solutions, typically with a random variable element. For some problems, lower learning rates help avoid local optima traps (like the robot falling over face first, because of a reward for going forward).
I was wondering what this ‘grad_norm’ parameter is. I got sidetracked by the paper with this name, which is maybe even unrelated. I haven’t gone to the Tune website yet to check if it’s the same thing. The grad_norm I was looking for is in the ARS code.
grad_norm gets smaller as episode_reward_mean gets bigger. So, gradient normalisation… gradient normalisation… still not sure.
info = {
“weights_norm”: np.square(theta).sum(),
“weights_std”: np.std(theta),
“grad_norm”: np.square(g).sum(),
“update_ratio”: update_ratio,
“episodes_this_iter”: noisy_lengths.size,
“episodes_so_far”: self.episodes_so_far,
}
So, it’s the sum of the square of g… and g is… the total of the ‘batched weighted sum’ of the ARS perturbation results, I think… but it’s not theta… which is the policy itself. Right, so the policy is the current agent/model brains, and g would be the average of the rollout tests, and so grad_norm, as a sum of squares is like the square of variance, so it’s a sort of measure of how much weights are changing, i think.
# Compute and take a step.
g, count = utils.batched_weighted_sum(
noisy_returns[:, 0] - noisy_returns[:, 1],
(self.noise.get(index, self.policy.num_params)
for index in noise_idx),
batch_size=min(500, noisy_returns[:, 0].size))
g /= noise_idx.size
# scale the returns by their standard deviation
if not np.isclose(np.std(noisy_returns), 0.0):
g /= np.std(noisy_returns)
assert (g.shape == (self.policy.num_params, )
and g.dtype == np.float32)
# Compute the new weights theta.
theta, update_ratio = self.optimizer.update(-g)
# Set the new weights in the local copy of the policy.
self.policy.set_flat_weights(theta)
# update the reward list
if len(all_eval_returns) > 0:
self.reward_list.append(eval_returns.mean())
def batched_weighted_sum(weights, vecs, batch_size):
total = 0
num_items_summed = 0
for batch_weights, batch_vecs in zip(
itergroups(weights, batch_size), itergroups(vecs, batch_size)):
assert len(batch_weights) == len(batch_vecs) <= batch_size
total += np.dot(
np.asarray(batch_weights, dtype=np.float32),
np.asarray(batch_vecs, dtype=np.float32))
num_items_summed += len(batch_weights)
return total, num_items_summed
Well anyway. I found another GradNorm.
GradNorm
https://arxiv.org/pdf/1711.02257.pdf – “We present a gradient normalization (GradNorm) algorithm that automatically balances training in deep multitask models by dynamically tuning gradient magnitudes.”
Conclusions We introduced GradNorm, an efficient algorithm for tuning loss weights in a multi-task learning setting based on balancing the training rates of different tasks. We demonstrated on both synthetic and real datasets that GradNorm improves multitask test-time performance in a variety of scenarios, and can accommodate various levels of asymmetry amongst the different tasks through the hyperparameter α. Our empirical results indicate that GradNorm offers superior performance over state-of-the-art multitask adaptive weighting methods and can match or surpass the performance of exhaustive grid search while being significantly less time-intensive.
Looking ahead, algorithms such as GradNorm may have applications beyond multitask learning. We hope to extend the GradNorm approach to work with class-balancing and sequence-to-sequence models, all situations where problems with conflicting gradient signals can degrade model performance. We thus believe that our work not only provides a robust new algorithm for multitask learning, but also reinforces the powerful idea that gradient tuning is fundamental for training large, effective models on complex tasks.
…
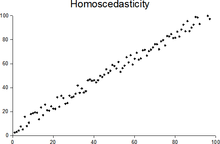
The paper derived the formulation of the multitask loss based on the maximization of the Gaussian likelihood with homoscedastic* uncertainty. I will not go to the details here, but the simplified forms are strikingly simple.
In statistics, a sequence (or a vector) of random variables is homoscedastic /ˌhoʊmoʊskəˈdæstɪk/ if all its random variables have the same finite variance. This is also known as homogeneity of variance. The complementary notion is called heteroscedasticity.
https://en.wikipedia.org/wiki/Hessian_matrix some sort of crazy math thing I’ve come across while researching NNs. My own opinion is that neurons in the brain are not doing any calculus, and to my knowledge, there’s still no proof of back-propagation in the brain, so whenever the math gets too complicated, there’s probably a simpler way to do it.
In mathematics, the Hessian matrix or Hessian is a square matrix of second-order partial derivatives of a scalar-valued function, or scalar field. It describes the local curvature of a function of many variables. The Hessian matrix was developed in the 19th century by the German mathematician Ludwig Otto Hesse and later named after him. Hesse originally used the term “functional determinants”.
A function ff of two independent variables xx and yy has two first order partial derivatives, fxfx and fy.fy. Each of these first-order partial derivatives has two partial derivatives, giving a total of four second-order partial derivatives:
Intuitively, if each distribution is viewed as a unit amount of “dirt” piled on {M}, the metric is the minimum “cost” of turning one pile into the other, which is assumed to be the amount of dirt that needs to be moved times the mean distance it has to be moved. Because of this analogy, the metric is known in computer science as the earth mover’s distance.
“Sparse coding is a representation learning method which aims at finding a sparse representation of the input data in the form of a linear combination of basic elements as well as those basic elements themselves. These elements are called atoms and they compose a dictionary. “
:That is true. As I wrote earlier, PyTorch is a jacobian-vector product engine. In the process it never explicitly constructs the whole Jacobian. It’s usually simpler and more efficient to compute the JVP directly.:
Dot product is a scalar magnitude. You take the X components of both and multiply them together, and take the Y components of both and multiply them together, and then add those.
Algebraically, the dot product is the sum of the products of the corresponding entries of the two sequences of numbers. Geometrically, it is the product of the Euclidean magnitudes of the two vectors and the cosine of the angle between them. These definitions are equivalent when using Cartesian coordinates.
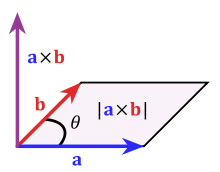
The Cross Product
The cross product a × b is defined as a vector c that is perpendicular (orthogonal) to both a and b, with a direction given by the right-hand rule and a magnitude equal to the area of the parallelogram that the vectors span.
Kinematics is the study of motion of bodies without regard to the forces that cause the motion. Dynamics on the other hand is the study of the motion of bodies due to applied forces (think F=ma). For example consider orbital mechanics: Kepler’s Laws are kinematic, in that they describe characteristics of a satellite’s orbit such as its eliptical shape without considering the forces that cause that motion, whereas Newton’s Law of Gravity is dynamic as it incorporates the force of gravity to describe why the orbit is eliptical.



 .
.