We’ve spoken with Dr. Maksimiljan Brus, at the University of Maribor, and he’s sent us some WAV file recordings of a large group of chickens.
There seems to be a decent amount of work done, particularly at Georgia Tech, regarding categorizing chicken sounds, to detect stress, or bronchitis, etc. They’ve also done some experiments to see how chickens react to humans and robots. (It takes them about 3 weeks to get used to either).
In researching the topic, there was a useful South African document related to smallholding size chicken businesses. It covers everything. Very good resource, actually, and puts into perspective the relative poverty in the communities where people sell chickens for a living. The profit margin per chicken in 2013 was about R12 per live chicken (less than 1 euro).

for Small-Scale Broiler Enterprises
K Ralivhesa, W van Averbeke
& FK Siebrits
So anyway, I’m having a look at the sound files, to see what data and features I can extract. There’s no labels, so there won’t be any reinforcement learning here. Anomaly detection doesn’t need labels, and can use moving window statistics, to notice when something is out of the ordinary. So that’s what I’m looking into.
I am personally interested in Numenta’s algorithms, such as HTM, which use a model of cortical columns, and sparse encodings, to predict, and detect anomalies. I looked into getting Nupic.critic working, but Nupic is so old now, written in Python 2, that it’s practically impossible to get working. There is a community fork, htm.core, updated to Python 3, but it’s missing parts of the nupic codebase that nupic.critic is relying on. I’m able to convert the sound files to the nupic format, but am stuck for now, when running the analysis.
So let’s start at a more basic level and work our way up.
I downloaded Praat, an interesting sound analysis program used for some audio research. Not sure if it’s useful here. But it’s able to show various sound features. I’ll close it again, for now.

So, first thing to do, is going to be Mel spectrograms, and possibly Mel Frequency Cepstral Coefficients (MFCCs). The Mel scale kinda allows a difference between 250Hz and 500Hz to be scaled to the same size as a difference between 13250Hz and 13500Hz. It’s log-scaled.
Mel spectrograms let you use visual tools on audio. Also, worth knowing what a feature is, in machine learning. It’s a measurable property.
Ok where to start? Maybe librosa and PyOD?
pip install librosa
Ok and this outlier detection medium writeup, PyOD, says
Neural Networks
Neural networks can also be trained to identify anomalies.
Autoencoder (and variational autoencoder) network architectures can be trained to identify anomalies without labeled instances. Autoencoders learn to compress and reconstruct the information in data. Reconstruction errors are then used as anomaly scores.
More recently, several GAN architectures have been proposed for anomaly detection (e.g. MO_GAAL).
There’s also the results of a group working on this sort of problem, here.
A relevant arxiv too:
ANOMALOUS SOUND DETECTION BASED ON
INTERPOLATION DEEP NEURAL NETWORK
And
UNSUPERVISED ANOMALOUS SOUND DETECTION VIA AUTOENCODER APPROACH
What is this DCASE?
Hmm so there is a challenge for it currently. It’s big in Japan. Here’s the winning solution:
Amazon programmers win an Amazon competition on anomaly detection.
Here was an illustrative example of an anomaly, of some machine sound.
And of course, there are more traditional? algorithms, (data-science algorithms). Here’s a medium article overview, for a submission to a heart murmur challenge. It mentions kapre, “Keras Audio Preprocessors – compute STFT, ISTFT, Melspectrogram, and others on GPU real-time.”
And I found ‘torchaudio‘,
Here’s a useful flowchart from a paper about edge sound analysis on a Teensy. Smart Audio Sensors (SASs). The code “computes the FFT and Mel coefficients of a recorded audio frame.”

Edge for Anomaly Detection
I haven’t mentioned it, but of course FFT, Fast Fourier Transform, which converts audio to frequency bands, is going to be a useful tool, too. “The FFT’s importance derives from the fact that it has made working in the frequency domain equally computationally feasible as working in the temporal or spatial domain. ” – (wikipedia)
On the synthesis and possibly artistic end, there’s also MelGAN and the like.
Google’s got pipelines in kubernetes ? MLOps stuff.
Artistically speaking, it sounds like we want spectrograms. Someone implements one from scratch here, and there is a link to a good youtube video on relevant sound analysis ideas. Wide-band, vs. narrow-band, for example. Overlapping windows? They’re explaining STFT, which is used to make spectrograms.
There’s also something called Chirp Z transform.
Anyway. Good stuff. As always, I find the hardest part is finding your way back to your various dev environments. Ok I logged into the Jupyter running in the docker on the Jetson. ifconfig to get the ip, and http://192.168.101.115:8888/lab, voila).
Ok let’s see torchaudio’s colab… and pip install, ok… Here’s a summary of the colab.
Some ghostly Mel spectrogram stuff. Also, interesting ‘To recover a waveform from spectrogram, you can use GriffinLim.’

Ok let’s get our own dataset prepared. We need an anomaly detector. Let’s see…
———————— <LIBROSA INSTALLATION…> —————
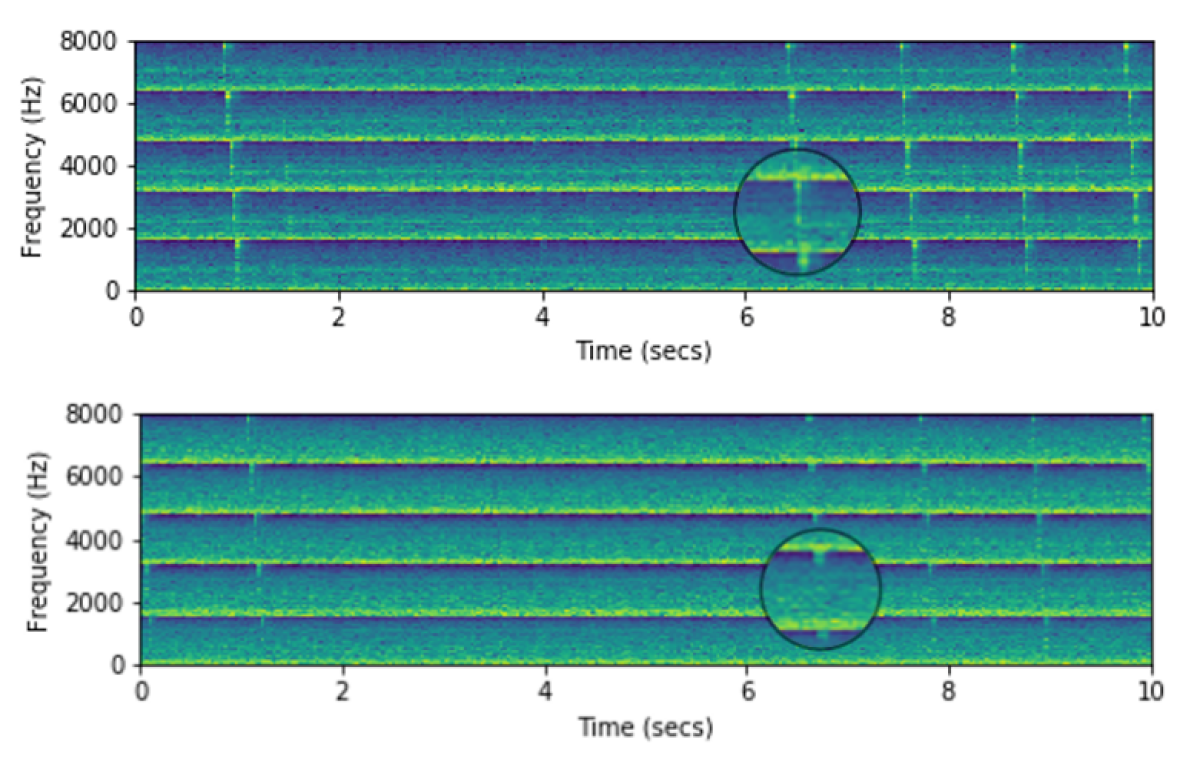
Ok the librosa mel spectrogram is working, at least, so far. So these are the images for the 4 files Dr. Brus sent.

While looking for something like STFT to make a spectogram video, i came across this resource: Machine Hearing. Also this tome of ML resources.
Classification is maybe the best way to do this ML stuff. Then you can add labels to classes, and train a neural network to associate labels, and to categorise. So it would be ideal, if the data were pre-labelled, i.e. classified by chicken stress vocalisation experts. Like here is a soundset with metadata, that lets you classify sounds with labels, (with training).
So we really do need to use an anomaly detection algorithm, because I listened to the chickens for a little bit, and I’m not getting the nuances.
Here’s a relevant paper, which learns classes, for retroactive labelling. They’re recording a machine making sounds, and then humans label it. They say 1NN (k-nearest-neighbours) is hard to beat, but it’s memory intensive. “Nearest centroid (NC) combined with DBA has been shown to be competitive with kNN at a much smaller computational cost”.
Here’s pyAudioAnalysis
Perform unsupervised segmentation (e.g. speaker diarization) and extract audio thumbnails
- Train and use audio regression models (example application: emotion recognition)
- Apply dimensionality reduction to visualize audio data and content similarities
Here’s a cool visualiser, in tensorboard,

Ideally, I would like to use NuPIC.
Ok, let’s hope this old link works, for a nupic docker.
sudo docker run -i -t numenta/nupic /bin/bash
Ok amazing. Ok right, trying to install matplotlib inside the docker crashes. urllib3. I’ve been here before. Right, I asked on the github issues. 14 days ago, I asked. I got htm.core working. But it doesn’t have nupic.data classes.
After bashing my head against the apparent impossibility to pip install urllib3 and matplotlib in a python 2.7 docker, I’ve decided I will have to port the older nupic.critic or nupic.audio code to htm.core.
I cleared up some harddrive space, and ran this docker:
docker run -d -p 8888:8888 --name jupyter 3rdman/htm.core-jupyter:latest then get the token for the URL: docker logs -f jupyter
There’s a lot to go through, and I’m a noob at HTM. So I will start a new article now, on HTM specifically, for this.