I have the Jetson NX, and I tried the last couple of days to install OpenCV, and am still fighting it. But we’re going to give it a few rounds.
Let’s see, so I used DustyNV’s Dockerfile with an OpenCV setup for 4.4 or 4.5.
But the build dies, or is still missing libraries. There’s a bunch of them, and as I’m learning, everything is a linker issue. Everything. sudo ldconfig.
Here’s a 2019 quora answer to “What is sudo ldconfig in linux?”
“ldconfig updates the cache for the linker in a UNIX environment with libraries found in the paths specified in “/etc/ld.so.conf”. sudo executes it with superuser rights so that it can write to “/etc/ld.so.cache”.
You usually use this if you get errors about some dynamically linked libraries not being found when starting a program although they are actually present on the system. You might need to add their paths to “/etc/ld.so.conf” first, though.” – Marcel Noe
So taking my own advice, let’s see:
chicken@chicken:/etc/ld.so.conf.d$ find | xargs cat $1
cat: .: Is a directory
/opt/nvidia/vpi1/lib64
/usr/local/cuda-10.2/targets/aarch64-linux/lib
# Multiarch support
/usr/local/lib/aarch64-linux-gnu
/lib/aarch64-linux-gnu
/usr/lib/aarch64-linux-gnu
/usr/lib/aarch64-linux-gnu/libfakeroot
# libc default configuration
/usr/local/lib
/usr/lib/aarch64-linux-gnu/tegra
/usr/lib/aarch64-linux-gnu/fakechroot
/usr/lib/aarch64-linux-gnu/tegra-egl
/usr/lib/aarch64-linux-gnu/tegra
Ok. On our host (Jetson), let’s see if we can install it, or access it. It’s Jetpack 4.6.1 so it should have it installed already.
ImportError: libblas.so.3: cannot open shared object file: No such file or directory
cd /usr/lib/aarch64-linux-gnu/
ls -l liblas.so*
libblas.so -> /etc/alternatives/libblas.so-aarch64-linux-gnu
cd /etc/alternatives
ls -l liblas.so*
libblas.so.3-aarch64-linux-gnu -> /usr/lib/aarch64-linux-gnu/atlas/libblas.so.3
libblas.so-aarch64-linux-gnu -> /usr/lib/aarch64-linux-gnu/atlas/libblas.so
Sounds promising. Ha it worked.
chicken@chicken:/usr/lib/aarch64-linux-gnu/atlas$ python3
Python 3.6.9 (default, Dec 8 2021, 21:08:43)
[GCC 8.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import cv2
>>>
Now let’s try fix DustyNV’s Dockerfile. Oops right, it takes forever to build things, or even to download and install them. So try not to change things early on in the install. So besides, Dusty’s setup already has these being installed. So it’s not that it’s not there. It’s some linking issue.
Ok I start up the NV docker and try import cv2, but
admin@chicken:/workspaces/isaac_ros-dev$ python3
Python 3.6.9 (default, Jan 26 2021, 15:33:00)
[GCC 8.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import cv2
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.6/dist-packages/cv2/__init__.py", line 96, in <module>
bootstrap()
File "/usr/local/lib/python3.6/dist-packages/cv2/__init__.py", line 86, in bootstrap
import cv2
ImportError: libtesseract.so.4: cannot open shared object file: No such file or directory
admin@chicken:/$ sudo apt-get install libtesseract-dev
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following packages were automatically installed and are no longer required:
libarchive13 librhash0 libuv1
Use 'sudo apt autoremove' to remove them.
The following additional packages will be installed:
libleptonica-dev
The following NEW packages will be installed:
libleptonica-dev libtesseract-dev
0 upgraded, 2 newly installed, 0 to remove and 131 not upgraded.
Need to get 2,666 kB of archives.
After this operation, 14.1 MB of additional disk space will be used.
Do you want to continue? [Y/n] Y
Get:1 http://ports.ubuntu.com/ubuntu-ports bionic/universe arm64 libleptonica-dev arm64 1.75.3-3 [1,251 kB]
Get:2 http://ports.ubuntu.com/ubuntu-ports bionic/universe arm64 libtesseract-dev arm64 4.00~git2288-10f4998a-2 [1,415 kB]
Fetched 2,666 kB in 3s (842 kB/s)
debconf: delaying package configuration, since apt-utils is not installed
Selecting previously unselected package libleptonica-dev.
dpkg: warning: files list file for package 'libcufft-10-2' missing; assuming package has no files currently installed
dpkg: warning: files list file for package 'cuda-cudart-10-2' missing; assuming package has no files currently installed
(Reading database ... 97997 files and directories currently installed.)
Preparing to unpack .../libleptonica-dev_1.75.3-3_arm64.deb ...
Unpacking libleptonica-dev (1.75.3-3) ...
Selecting previously unselected package libtesseract-dev.
Preparing to unpack .../libtesseract-dev_4.00~git2288-10f4998a-2_arm64.deb ...
Unpacking libtesseract-dev (4.00~git2288-10f4998a-2) ...
Setting up libleptonica-dev (1.75.3-3) ...
Setting up libtesseract-dev (4.00~git2288-10f4998a-2) ...
ImportError: libtesseract.so.4: cannot open shared object file: No such file or directory
This guy has a smart idea, to install them, which is pretty clever. But I tried that already, and tesseract’s build failed, of course. Then it complains about undefined references to jpeg,png,TIFF,zlib,etc. Hmm. All that shit is installed.
/usr/lib/gcc/aarch64-linux-gnu/8/../../../aarch64-linux-gnu/liblept.a(libversions.o): In function `getImagelibVersions':
(.text+0x98): undefined reference to `jpeg_std_error'
(.text+0x158): undefined reference to `png_get_libpng_ver'
(.text+0x184): undefined reference to `TIFFGetVersion'
(.text+0x1f0): undefined reference to `zlibVersion'
(.text+0x21c): undefined reference to `WebPGetEncoderVersion'
(.text+0x26c): undefined reference to `opj_version'
But so here’s the evidence: cv2 is looking for libtesseract.so.4, which doesn’t exist at all. And even if we symlinked it to point to the libtesseract.so file, that just links to libtesseract.so.4.0.0 which is empty.
Ah. Ok I had to sudo apt-get install libtesseract-dev on the Jetson host, not inside the docker!!. Hmm. Right. Cause I’m sharing most of the libs on the host anyway. It’s gotta be on the host.
admin@chicken:/usr/lib/aarch64-linux-gnu$ ls -l *tess*
-rw-r--r-- 1 root root 6892600 Apr 7 2018 libtesseract.a
lrwxrwxrwx 1 root root 21 Apr 7 2018 libtesseract.so -> libtesseract.so.4.0.0
lrwxrwxrwx 1 root root 21 Apr 7 2018 libtesseract.so.4 -> libtesseract.so.4.0.0
-rw-r--r-- 1 root root 3083888 Apr 7 2018 libtesseract.so.4.0.0
admin@chicken:/usr/lib/aarch64-linux-gnu$ python3
Python 3.6.9 (default, Jan 26 2021, 15:33:00)
[GCC 8.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import cv2
>>> exit()
Success.
So now back to earlier, we were trying to run jupyter lab, to try run the camera calibration code again. I added the installation to the dockerfile. So this command starts it up at http://chicken:8888/lab (or name of your computer).
Needed matplotlib, so just did quick macro install:
%pip install matplotlib
ModuleNotFoundError: No module named 'matplotlib'
Note: you may need to restart the kernel to use updated packages.
K... restart kernel. Kernel -> Restart.
Ok now I’m going to try calibrate the stereo cameras, since OpenCV is back.
Seems after some successes, the cameras are not creating capture sessions anymore, even from the host. Let’s reboot.
Here I’m continuing with the task of unsupervised detection of audio anomalies, hopefully for the purpose of detecting chicken stress vocalisations.
After much fussing around with the old Numenta NuPic codebase, I’m porting the older nupic.audio and nupic.critic code, over to the more recent htm.core.
These are the main parts:
Sparse Distributed Representation (SDR)
Encoders
Spatial Pooler (SP)
Temporal Memory (TM)
I’ve come across a very intricate implementation and documentation, about understanding the important parts in the HTM model, way deep, like how did I get here? I will try implement the ‘critic’ code, first. Or rather, I’ll try port it from nupic to htm. After further investigation, there’s a few options, and I’m going to try edit the hotgym example, and try shove wav files frequency band scalars through it instead of power consumption data. I’m simplifying the investigation. But I need to make some progress.
I’m using this docker to get in, mapping my code and wav file folder in:
docker run -d -p 8888:8888 --name jupyter -v /media/chrx/0FEC49A4317DA4DA/sounds/:/home/jovyan/work 3rdman/htm.core-jupyter:latest
So I've got some code working that writes to 'nupic format' (.csv) and code that reads the amplitudes from the csv file, and then runs it through htm.core.
So it takes a while, and it's just for 1 band (of 10 bands). I see it also uses the first 1/4 of so of the time to know what it's dealing with. Probably need to run it through twice to get predictive results in the first 1/4.
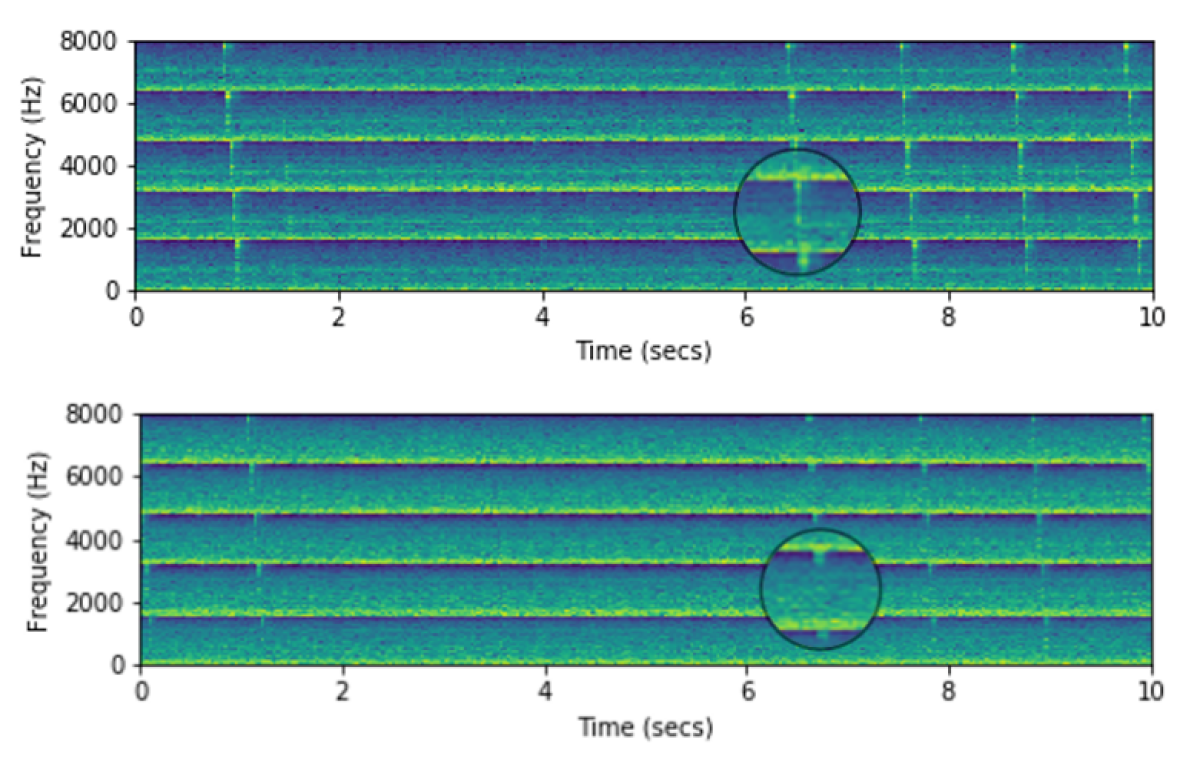
Ok no, after a few weeks, I've come back to this point, and realise that the top graph is the important one. Prediction is what's important. The bottom graphs are the anomaly scores, used by the prediction.
Frequency Band 0
The idea in nupic.critic, was to threshold changes in X bands. Let’s see the other graphs…
Frequency band 0: 0-480Hz ?Frequency band 2: 960-1440Hz ?Frequency band 3: 1440-1920Hz ? Frequency band 4: 1920-2400Hz ? Frequency band 5: 2400-2880Hz ? Frequency band 6: 2880-3360Hz ?
Ok Frequency bands 7, 8, 9 were all zero amplitude. So that’s the highest the frequencies went. Just gotta check what those frequencies are, again…
Opening 307.wav
Sample width (bytes): 2
Frame rate (sampling frequency): 48000
Number of frames: 20771840
Signal length: 20771840
Seconds: 432
Dimensions of periodogram: 4801 x 2163
Ok with 10 buckets, 4801 would divide into
Frequency band 0: 0-480Hz
Frequency band 1: 480-960Hz
Frequency band 2: 960-1440Hz
Frequency band 3: 1440-1920Hz
Frequency band 4: 1920-2400Hz
Frequency band 5: 2400-2880Hz
Frequency band 6: 2880-3360Hz
Ok what else. We could try segment the audio by band, so we can narrow in on the relevant frequency range, and then maybe just focus on that smaller range, again, in higher detail.
Learning features with some labeled data, is probably the correct way to do chicken stress vocalisation detections.
Unsupervised anomaly detection might be totally off, in terms of what an anomaly is. It is probably best, to zoom in on the relevant bands and to demonstrate a minimal example of what a stressed chicken sounds like, vs a chilled chicken, and compare the spectrograms to see if there’s a tell-tale visualisable feature.
A score from 1 to 5 for example, is going to be anomalous in arbitrary ways, without labelled data. Maybe the chickens are usually stressed, and the anomalies are when they are unstressed, for example.
A change in timing in music might be defined, in some way. like 4 out of 7 bands exhibiting anomalous amplitudes. But that probably won’t help for this. It’s probably just going to come down to a very narrow band of interest. Possibly pointing it out on a spectrogram that’s zoomed in on the feature, and then feeding the htm with an encoding of that narrow band of relevant data.
I’ll continue here, with some notes on filtering. After much fuss, the sox app (apt-get install sox) does it, sort of. Still working on python version.
$ sox 307_0_50.wav filtered_50_0.wav sinc -n 32767 0-480
$ sox 307_0_50.wav filtered_50_1.wav sinc -n 32767 480-960
$ sox 307_0_50.wav filtered_50_2.wav sinc -n 32767 960-1440
$ sox 307_0_50.wav filtered_50_3.wav sinc -n 32767 1440-1920
$ sox 307_0_50.wav filtered_50_4.wav sinc -n 32767 1920-2400
$ sox 307_0_50.wav filtered_50_5.wav sinc -n 32767 2400-2880
$ sox 307_0_50.wav filtered_50_6.wav sinc -n 32767 2880-3360
So, sox does seem to be working. The mel spectrogram is logarithmic, which is why it looks like this.
Visually, it looks like I'm interested in 2048 to 4096 Hz. That's where I can see the chirps.
Hmm. So I think the spectrogram is confusing everything.
So where does 4800 come from? 48 kHz. 48,000 Hz (48 kHz) is the sample rate “used for DVDs“.
Ah. Right. The spectrogram values represent buckets of 5 samples each, and the full range is to 24000…?
ok. So 2 x 24000. Maybe 2 channels? Anyway, full range is to 48000Hz. In that case, are the bands actually…
Frequency band 0: 0-4800Hz
Frequency band 1: 4800-9600Hz
Frequency band 2: 9600-14400Hz
Frequency band 3: 14400-19200Hz
Frequency band 4: 19200-24000Hz
Frequency band 5: 24000-28800Hz
Frequency band 6: 28800-33600Hz
Ok so no, it’s half the above because of the sample width of 2.
Frequency band 0: 0-2400Hz
Frequency band 1: 2400-4800Hz
Frequency band 2: 4800-7200Hz
Frequency band 3: 7200-9600Hz
Frequency band 4: 9600-12000Hz
Frequency band 5: 12000-14400Hz
Frequency band 6: 14400-16800Hz
So why is the spectrogram maxing at 8192Hz? Must be spectrogram sampling related.
So the original signal is 0 to 24000Hz, and the spectrogram must be 8192Hz because… the spectrogram is made some way. I’ll try get back to this when I understand it.
Ok i don’t entirely understand the last two. But basically the mel spectrogram is logarithmic, so those high frequencies really don’t get much love on the mel spectrogram graph. Buggy maybe.
So now I’m plotting the ‘chirp density’ (basically volume).
’98.wav’‘237.wav’‘307.wav’‘3072.wav’
In this scheme, we just proxy chirp volume density as a variable representing stress. We don’t know if it is a true proxy. As you can see, some recordings have more variation than others.
Some heuristic could be decided upon, for rating the stress from 1 to 5. The heuristic depends on how the program would be used. For example, if it were streaming audio, for an alert system, it might alert upon some duration of time spent above one standard deviation from the rolling mean. I’m not sure how the program would be used though.
If the goal were to differentiate stressed and not stressed vocalisations, that would require labelled audio data.
We’ve spoken with Dr. Maksimiljan Brus, at the University of Maribor, and he’s sent us some WAV file recordings of a large group of chickens.
There seems to be a decent amount of work done, particularly at Georgia Tech, regarding categorizing chicken sounds, to detect stress, or bronchitis, etc. They’ve also done some experiments to see how chickens react to humans and robots. (It takes them about 3 weeks to get used to either).
In researching the topic, there was a useful South African document related to smallholding size chicken businesses. It covers everything. Very good resource, actually, and puts into perspective the relative poverty in the communities where people sell chickens for a living. The profit margin per chicken in 2013 was about R12 per live chicken (less than 1 euro).
From PRODUCTION GUIDELINES for Small-Scale Broiler Enterprises K Ralivhesa, W van Averbeke & FK Siebrits
So anyway, I’m having a look at the sound files, to see what data and features I can extract. There’s no labels, so there won’t be any reinforcement learning here. Anomaly detection doesn’t need labels, and can use moving window statistics, to notice when something is out of the ordinary. So that’s what I’m looking into.
I am personally interested in Numenta’s algorithms, such as HTM, which use a model of cortical columns, and sparse encodings, to predict, and detect anomalies. I looked into getting Nupic.critic working, but Nupic is so old now, written in Python 2, that it’s practically impossible to get working. There is a community fork, htm.core, updated to Python 3, but it’s missing parts of the nupic codebase that nupic.critic is relying on. I’m able to convert the sound files to the nupic format, but am stuck for now, when running the analysis.
So let’s start at a more basic level and work our way up.
I downloaded Praat, an interesting sound analysis program used for some audio research. Not sure if it’s useful here. But it’s able to show various sound features. I’ll close it again, for now.
So, first thing to do, is going to be Mel spectrograms, and possibly Mel Frequency Cepstral Coefficients (MFCCs). The Mel scale kinda allows a difference between 250Hz and 500Hz to be scaled to the same size as a difference between 13250Hz and 13500Hz. It’s log-scaled.
Mel spectrograms let you use visual tools on audio. Also, worth knowing what a feature is, in machine learning. It’s a measurable property.
Ok where to start? Maybe librosa and PyOD?
pip install librosa
Ok and this outlier detection medium writeup, PyOD, says
Neural Networks
Neural networks can also be trained to identify anomalies.
Autoencoder (and variational autoencoder) network architectures can be trained to identify anomalies without labeled instances. Autoencoders learn to compress and reconstruct the information in data. Reconstruction errors are then used as anomaly scores.
More recently, several GAN architectures have been proposed for anomaly detection (e.g. MO_GAAL).
There’s also the results of a group working on this sort of problem, here.
Here was an illustrative example of an anomaly, of some machine sound.
And of course, there are more traditional? algorithms, (data-science algorithms). Here’s a medium article overview, for a submission to a heart murmur challenge. It mentions kapre, “Keras Audio Preprocessors – compute STFT, ISTFT, Melspectrogram, and others on GPU real-time.”
Here’s a useful flowchart from a paper about edge sound analysis on a Teensy. Smart Audio Sensors (SASs). The code “computes the FFT and Mel coefficients of a recorded audio frame.”
Smart Audio Sensors in the Internet of Things Edge for Anomaly Detection
I haven’t mentioned it, but of course FFT, Fast Fourier Transform, which converts audio to frequency bands, is going to be a useful tool, too. “The FFT’s importance derives from the fact that it has made working in the frequency domain equally computationally feasible as working in the temporal or spatial domain. ” – (wikipedia)
On the synthesis and possibly artistic end, there’s also MelGAN and the like.
Google’s got pipelines in kubernetes ? MLOps stuff.
Artistically speaking, it sounds like we want spectrograms. Someone implements one from scratch here, and there is a link to a good youtube video on relevant sound analysis ideas. Wide-band, vs. narrow-band, for example. Overlapping windows? They’re explaining STFT, which is used to make spectrograms.
Anyway. Good stuff. As always, I find the hardest part is finding your way back to your various dev environments. Ok I logged into the Jupyter running in the docker on the Jetson. ifconfig to get the ip, and http://192.168.101.115:8888/lab, voila).
Ok let’s see torchaudio’s colab… and pip install, ok… Here’s a summary of the colab.
Some ghostly Mel spectrogram stuff. Also, interesting ‘To recover a waveform from spectrogram, you can use GriffinLim.’
Ok let’s get our own dataset prepared. We need an anomaly detector. Let’s see…
———————— <LIBROSA INSTALLATION…> —————
Ok the librosa mel spectrogram is working, at least, so far. So these are the images for the 4 files Dr. Brus sent.
While looking for something like STFT to make a spectogram video, i came across this resource: Machine Hearing. Also this tome of ML resources.
Classification is maybe the best way to do this ML stuff. Then you can add labels to classes, and train a neural network to associate labels, and to categorise. So it would be ideal, if the data were pre-labelled, i.e. classified by chicken stress vocalisation experts. Like here is a soundset with metadata, that lets you classify sounds with labels, (with training).
So we really do need to use an anomaly detection algorithm, because I listened to the chickens for a little bit, and I’m not getting the nuances.
Here’s a relevant paper, which learns classes, for retroactive labelling. They’re recording a machine making sounds, and then humans label it. They say 1NN (k-nearest-neighbours) is hard to beat, but it’s memory intensive. “Nearest centroid (NC) combined with DBA has been shown to be competitive with kNN at a much smaller computational cost”.
Ok, let’s hope this old link works, for a nupic docker.
sudo docker run -i -t numenta/nupic /bin/bash
Ok amazing. Ok right, trying to install matplotlib inside the docker crashes. urllib3. I’ve been here before. Right, I asked on the github issues. 14 days ago, I asked. I got htm.core working. But it doesn’t have nupic.data classes.
After bashing my head against the apparent impossibility to pip install urllib3 and matplotlib in a python 2.7 docker, I’ve decided I will have to port the older nupic.critic or nupic.audio code to htm.core.
I cleared up some harddrive space, and ran this docker:
docker run -d -p 8888:8888 --name jupyter 3rdman/htm.core-jupyter:latest
then get the token for the URL:
docker logs -f jupyter
There’s a lot to go through, and I’m a noob at HTM. So I will start a new article now, on HTM specifically, for this.
I applied for the OpenAI Codex beta, and tried it out. It’s very cool.
It’s like GPT trained on Github or something like that, so you can just give it a prompt, and it tries to carry on the sentence with what it expects next.
So the easy way to use it, I’ve found, is to write a comment for the code you want it to write for you. I switched the engine to ‘davinci-codex’ and cranked up the response length to 1600 or so. Sometimes it just makes up more comments, or does something silly. But now and then it hits a home run.
Here’s an example.
"""
Take an example wav file, found at file_name="/home/jovyan/work/307.wav", and plot a mel spectrogram of it.
"""
import librosa
import librosa.display
import matplotlib.pyplot as plt
file_name="/home/jovyan/work/307.wav"
y, sr = librosa.load(file_name)
plt.figure(figsize=(12, 4))
librosa.display.waveplot(y, sr=sr)
plt.show()
S = librosa.feature.melspectrogram(y, sr=sr, n_mels=128)
log_S = librosa.power_to_db(S, ref=np.max)
plt.figure(figsize=(12, 4))
librosa.display.specshow(log_S, sr=sr, x_axis='time', y_axis='mel')
plt.title('mel power spectrogram')
plt.colorbar(format='%+02.0f dB')
plt.tight_layout()
plt.show()
I had to install librosa, but then it worked. It did more than I asked for.
Then I fed that whole thing, with another
""" Plot the MFCC of file_name="/home/jovyan/work/307.wav" """
and it carried like an example giving champ:
"""
Take an example wav file, found at file_name="/home/jovyan/work/307.wav", and plot a mel spectrogram of it.
"""
import librosa
import librosa.display
import matplotlib.pyplot as plt
file_name="/home/jovyan/work/307.wav"
y, sr = librosa.load(file_name)
plt.figure(figsize=(12, 4))
librosa.display.waveplot(y, sr=sr)
plt.show()
S = librosa.feature.melspectrogram(y, sr=sr, n_mels=128)
log_S = librosa.power_to_db(S, ref=np.max)
plt.figure(figsize=(12, 4))
librosa.display.specshow(log_S, sr=sr, x_axis='time', y_axis='mel')
plt.title('mel power spectrogram')
plt.colorbar(format='%+02.0f dB')
plt.tight_layout()
plt.show()
"""
Plot the MFCC of file_name="/home/jovyan/work/307.wav"
"""
import librosa
import librosa.display
import matplotlib.pyplot as plt
file_name="/home/jovyan/work/307.wav"
y, sr = librosa.load(file_name)
plt.figure(figsize=(12, 4))
librosa.display.waveplot(y, sr=sr)
plt.show()
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=40)
plt.figure(figsize=(12, 4))
librosa.display.specshow(mfccs, x_axis='time')
plt.colorbar()
plt.title('MFCC')
plt.tight_layout()
plt.show()
"""
Plot the chromagram of file_name="/home/jovyan/work/307.wav"
"""
import librosa
import librosa.display
import matplotlib.pyplot as plt
file_name="/home/jovyan/work/307.wav"
y, sr = librosa.load(file_name)
plt.figure(figsize=(12, 4))
librosa.display.waveplot(y, sr=sr)
plt.show()
chroma = librosa.feature.chroma_stft(y=y, sr=sr)
plt.figure(figsize=(12, 4))
librosa.display.specshow(chroma, y_axis='chroma', x_axis='time')
plt.colorbar()
plt.title('Chromagram')
plt.tight_layout()
plt.show()
"""
Plot the chromagram of file_name="/home/jovyan/work/307.wav"
"""
import librosa
import librosa.display
import matplotlib.pyplot as plt
file_name="/home/jovyan/work/307.wav"
y, sr = librosa.load(file_name)
plt.figure(figsize=(12, 4))
librosa.display.waveplot(y, sr=sr)
plt.show()
chroma = librosa.feature.chroma_stft(y=y, sr=sr)
plt.figure(figsize=(12, 4))
librosa.display.specshow(chroma, y_axis='chroma', x_axis='time')
plt.colorbar()
plt.title('Chromagram')
plt.tight_layout()
plt.show()
"""
Plot the tonnetz of file_name="/home/jovyan/work/307.wav"
"""
import librosa
import librosa.display
import matplotlib.pyplot as plt
file_name="/home/jovyan/work/307.wav"
y, sr = librosa.load(file_name)
plt.figure(figsize=(12, 4))
librosa.display.waveplot(y, sr=sr)
plt.show()
tonnetz = librosa.feature.tonnetz(y=y, sr=sr)
plt.figure(figsize=(12, 4))
librosa.display.specshow(tonnetz, y_axis='tonnetz', x_axis='time')
plt.colorbar()
plt.title('Tonal Centroids (Tonnetz)')
plt.tight_layout()
plt.show()
"""
Plot the zero-crossing rate of file_name="/home/jovyan/work/307.wav"
"""
import librosa
import librosa.display
import matplotlib.pyplot as plt
file_name="/home/jovyan/work/307.wav"
y, sr = librosa.load(file_name)
plt.figure(figsize=(12, 4))
librosa.display.waveplot(y, sr=sr)
plt.show()
zrate = librosa.feature.zero_crossing_rate(y)
plt.figure(figsize=(12, 4))
librosa.display.specshow(zrate, x_axis='time')
plt.colorbar()
plt.title('Zero Crossing Rate')
plt.tight_layout()
plt.show()
"""
Plot the spectral centroid of file_name="/home/jovyan/work/307.wav"
"""
import librosa
import librosa.display
import matplotlib.pyplot as plt
file_name="/home/jovyan/work/307.wav"
y, sr = librosa.load(file_name)
plt.figure(figsize=(12, 4))
librosa.display.waveplot(y, sr=sr)
plt.show()
cent = librosa.feature.spectral_centroid(y=y, sr=sr)
plt.figure(figsize=(12, 4))
librosa.display.specshow(cent, x_axis='time')
plt.colorbar()
plt.title('Spectral Centroids')
plt.tight_layout()
plt.show()
"""
Plot the spectral bandwidth of file_name="/home/jovyan/work/307.wav"
"""
import librosa
import librosa.display
import matplotlib.pyplot as plt
file_name="/home/jovyan/work/307.wav"
y, sr = librosa.load(file_name)
plt.figure(figsize=(12, 4))
librosa.display.waveplot(y, sr=sr)
plt.show()
spec_bw = librosa.feature.spectral_bandwidth(y=y, sr=sr)
plt.figure(figsize=(12, 4))
librosa.display.specshow(spec_bw, x_axis='time')
plt.colorbar()
plt.title('Spectral Bandwidth')
plt.tight_layout()
plt.show()
"""
Plot the spectral rolloff of file_name="/home/jovyan/work/307.wav"
"""
import librosa
import librosa.display
import matplotlib.pyplot as plt
file_name="/home/jovyan/work/307.wav"
y, sr = librosa.load(file_name)
plt.figure(figsize=(12, 4))
librosa.display.waveplot(y, sr=sr)
plt.show()
spec_rolloff = lib
After waiting a while… we get:
Ok, Chromagram twice… bold move, Codex.
import librosa
import librosa.display
import matplotlib.pyplot as plt
file_name="/home/jovyan/work/307.wav"
y, sr = librosa.load(file_name)
plt.figure(figsize=(12, 8))
D = librosa.amplitude_to_db(np.abs(librosa.stft(y)), ref=np.max)
plt.subplot(4, 2, 1)
librosa.display.specshow(D, y_axis='linear')
plt.colorbar(format='%+2.0f dB')
plt.title('Linear-frequency power spectrogram')
plt.subplot(4, 2, 2)
librosa.display.specshow(D, y_axis='log')
plt.colorbar(format='%+2.0f dB')
plt.title('Log-frequency power spectrogram')
plt.subplot(4, 2, 3)
librosa.display.specshow(D, x_axis='time')
plt.colorbar(format='%+2.0f dB')
plt.title('Time-frequency power spectrogram')
plt.subplot(4, 2, 4)
librosa.display.specshow(D, x_axis='time', y_axis='log')
plt.colorbar(format='%+2.0f dB')
plt.title('Log-Time-frequency power spectrogram')
We’ve got an egg in the gym environment now, so we need to collect some data for training the robot to go pick up an egg.
I’m going to have it save the rgba, depth and segmentation images to disk for Unet training. I left out the depth image for now. The pictures don’t look useful. But some papers are using the depth, so I might reconsider. Some weed bot paper uses 14-channel images with all sorts of extra domain specific data relevant to plants.
I wrote some code to take pics if the egg was in the viewport, and it took 1000 rgb and segmentation pictures or so. I need to change the colour of the egg for sure, and probably randomize all the textures a bit. But main thing is probably to make the segmentation layers with pixel colours 0,1,2, etc. so that it detects the egg and not so much the link in the foreground.
So sigmoid to softmax and so on. Switching to multi-class also begs the question whether to switch to Pytorch & COCO panoptic segmentation based training. It will have to happen eventually, as I think all of the fastest implementations are currently in Pytorch and COCO based. Keras might work fine for multiclass or multiple binary classification, but it’s sort of the beginning attempt. Something that works. More proof of concept than final implementation. But I think Keras will be good enough for these in-simulation 256×256 images.
Regarding multi-class segmentation, karolzak says “it’s just a matter of changing num_classes argument and you would need to shape your mask in a different way (layer per class??), so for multiclass segmentation you would need a mask of shape (width, height, num_classes)“
I’ll keep logging my debugging though, if you’re reading this.
So I ran segmask_linkindex.py to see what it does, and how to get more useful data. The code is not running because the segmentation image actually has an array of arrays. I presume it’s a numpy array. I think it must be the rows and columns. So anyway I added a second layer to the loop, and output the pixel values, and when I ran it in the one mode:
Ok I see. Hmm. Well the important thing is that this code is indeed for extracting the pixel information. I think it’s going to be best for the segmentation to use the simpler segmentation mask that doesn’t track the link info. Ok so I used that code from the guy’s thesis project, and that was interpolating the numbers. When I look at the unique elements of the mask without interpolation, I’ve got…
[ 0 2 255]
[ 0 2 255]
[ 0 2 255]
[ 0 2 255]
[ 0 2 255]
[ 0 1 2 255]
[ 0 1 2 255]
[ 0 2 255]
[ 0 2 255]
Ok, so I think:
255 is the sky
0 is the plane
2 is the robotable
1 is the egg
So yeah, I was just confused because the segmentation masks were all black and white. But if you look closely with a pixel picker tool, the pixel values are (0,0,0), (1,1,1), (2,2,2), (255,255,255), so I just couldn’t see it.
The interpolation kinda helps, to be honest.
As per OpenAI’s domain randomization helping with Sim2Real, we want to randomize some textures and some other things like that. I also want to throw in some random chickens. Maybe some cats and dogs. I’m afraid of transfer learning, at this stage, because a lot of it has to do with changing the structure of the final layer of the neural network, and that might be tough. Let’s just do chickens and eggs.
Both techniques increase the computational requirements: dynamics randomization slows training down by a factor of 3x, while learning from images rather than states is about 5-10x slower.
Ok that’s a bit more complex than I was thinking. I want to randomize textures and colours, first
I’ve downloaded and unzipped the ‘Describable Textures Dataset’
And ok it’s loading a random texture for the plane
and random colour for the egg and chicken
Ok, next thing is the Simulation CNN.
Interpolation doesn’t work though, for this, cause it interpolates from what’s available in the image:
[ 0 85 170 255]
[ 0 63 127 191 255]
[ 0 63 127 191 255]
I kind of need the basic UID segmentation.
[ 0 1 2 3 255]
Ok, pity about the mask colours, but anyway.
Let’s train the UNet on the new dataset.
We’ll need to make karolzak’s changes.
I’ve saved 2000+ rgb.jpg and seg.png files and we’ve got [0,1,2,3,255] [plane, egg, robot, chicken, sky]
So num_classes=5
And
“for multiclass segmentation you would need a mask of shape (width, height, num_classes) “
What is y.shape?
(2001, 256, 256, 1)
which is 2001 files, of 256 x 256 pixels, and one class. So if I change that to 5…? ValueError: cannot reshape array of size 131137536 into shape (2001,256,256,5)
Um… Ok I need to do more research. Brb.
So the keras_unet library is set up to input binary masks per class, and output binary masks per class.
I coded it up using the library author’s suggested method, as he pointed out that the gains of the integer encoding method are minimal. I’ll check it out another time. I think it might still make sense for certain cases.
Ok that’s pretty awesome. We have 4 masks. Human, chicken, egg, robot. I left out plane and sky for now. That was just 2000 images of training, and I have 20000. I trained on another 2000 images, and it’s down to 0.008 validation loss, which is good enough!
So now I want to load the CNN model in the locomotion code, and feed it the images from the camera, and then have a reward function related to maximizing the egg pixels.
I also need to look at the pybullet-planning project and see what it consists of, as I imagine they’ve made some progress on the next steps. “built-in implementations of standard motion planners, including PRM, RRT, biRRT, A* etc.” – I haven’t even come across these acronyms yet! Ok, they are motion planning. Solvers of some sort. Hmm.
The attempted training of the U-Net on the Jetson NX has been a bit slow, making odd progress over 2 nights, and I’m not sure if it’s working. I’ve had to reduce batch size to 1, and the filter size, which has reduced the number of parameters by about a factor of 10, and still, loading the NN into memory sometimes dies on a concatenation call. The number of images per batch can also crash it, so perhaps some memory can be saved with a better image loading process.
Anyway, projects under an official NVIDIA repo are suggesting that we should be able to train smaller networks like resnet18, with 11 million parameters, on the Jetson. So maybe we can still avoid the cloud.
But judging by the NVIDIA TLT info, any training of resnet50s or 100s are going to need serious GPUs and memory and space for training.
After looking at Google, Amazon and Microsoft offerings, the AWS g4dn.xlarge instance looks like it might be the best option, at $0.526/hr, or Google’s got a T4 based compute engine for only $0.35/hr. These are good options, if 16GB of video ram will be enough. It should be, because we’re working with like 5GB on the Jetson.
Microsoft has the NC6 option, which looks good for a much more beefy GPU and memory, at $0.90/hr.
We’re just looking at Pay-as-you-go prices, as the 1-year and 3-year commitments will end up being expensive.
I’m still keen to try train on the Jetson, but the cloud is becoming more and more probable. In Sweden, visiting Miranda, we’re unable to order a Jetson AGX Xavier, the 32GB version. Arrow won’t ship here without a VAT number, and SiliconHighway is out of stock.
So, attempting Cloud GPUs. If you want to cut to the chase, read this one backwards. So many problems. In the end, it turned out setting it up yourself is practically impossible, but there is an ‘AI Platform’ section that works.
Amazon AWS. Tried to log in to AWS. “Authentication failed because your account has been suspended.” Tells me to create a new account. But then brings me back to the same failure screen. Ok, sending email to their accounts department. Next.
Google Cloud. I tried to create a VM and add a T4 GPU, but none of the regions have them. So I need to download the Gcloud SDK and CLI tool first, to run a command to describe the regions, according to the ‘Before you begin‘ instructions..
Ok, GPUs will only run on N1 and A2 VMs. The A2 VMs are only for A100s, so I need an N1 VM in one of these regions, and we add a T4 GPU.
There’s an option to load a specific docker, and unfortunately they don’t seem to have one with both Pytorch and TF2. Let’s start with TF2 gcr.io/deeplearning-platform-release/tf2-gpu.2-4
So this looks like a good enough VM. 30GB RAM, 8 cpus. For europe-west3, the cost is about 50 cents / hr for the VM and 41 cents / hr for the GPU.
n1-standard-8
8
30GB
$0.4896
$0.09840
1 GPU
16 GB GDDR6
$0.41 per GPU
So let’s round up to about $1/hour. I ended up picking the n1-standard-4 (4 cpus, 15 gb ram).
At these prices I’ll want to get things up and running asap. So I am going to prep a bit, before I click the Create VM button.
I had to try a few things to find a cloud instance with a gpu, because the official list didn’t really work. I eventually got one with a T4 GPU from europe-west4-c.
It seems like Google Drive isn’t really part of the google cloud platform ecosystem, so I started a storage bucket with 50GB of space, and am uploading the chicken images to it.
The instance doesn’t have pip or jupyter installed. So let’s do that…
ok so when I sudo’ed, I got this error
Jul 20 14:45:01 chicken-vm konlet-startup[1665]: {"errorDetail":{"message":"write /var/lib/docker/tmp/GetImageBlob362062711: no space left on device"},"error":"write /var/lib/docker/tmp/GetImageBl
Jul 20 14:45:01 chicken-vm konlet-startup[1665]: ).
Jul 20 14:45:01 chicken-vm konlet-startup[1665]: 2021/07/20 14:43:04 No containers created by previous runs of Konlet found.
Jul 20 14:45:01 chicken-vm konlet-startup[1665]: 2021/07/20 14:43:04 Found 0 volume mounts in container chicken-vm declaration.
Jul 20 14:45:01 chicken-vm konlet-startup[1665]: 2021/07/20 14:43:04 Error: Failed to start container: Error: No such image: gcr.io/deeplearning-platform-release/tf2-gpu.2-4
Jul 20 14:45:01 chicken-vm konlet-startup[1665]: 2021/07/20 14:43:04 Saving welcome script to profile.d
So 10GB wasn’t enough to load gcr.io/deeplearning-platform-release/tf2-gpu.2-4 , I guess.
Ok deleting the VM. Next time, bigger hard drive. I’m now adding a cloud storage bucket and uploading the chicken images, so I can copy them to the VM’s drive later. It’s taking forever. Wow. Ok.
Now I am trying to spin up a VM again, and it’s practically impossible. I’ve tried every region and zone possible. Ok europe-west1-c. Finally. I also upped my ‘quota’ of gpus, under IAM->Quotas, in case that is a reason I couldn’t find a GPU VM. They reviewed and approved it in about 15 minutes.
+------------------+--------+-----------------+ | Name | Region | Requested Limit | +------------------+--------+-----------------+ | GPUS_ALL_REGIONS | GLOBAL | 1 | +------------------+--------+-----------------+
So after like 10 minutes of nothing, I see the docker container started up.
68ee22bf268f gcr.io/deeplearning-platform-release/tf2-gpu.2-4 "/entrypoint.sh /run…" 5 minutes ago Up 4 minutes klt-chicken-vm-template-1-ursn
I’ve enabled tcp:8080 port in the firewall settings, but the external ip and new port don’t seem to connect. https://35.195.66.139:8080/ Ah ha. http. We’re in!
Jupyter Lab starting up.
So I tried to download the gcloud tools to get gsutil to access my storage bucket, but was getting ‘Permission denied’, even as root. I chown’ed it to my user, but still no.
I had to go out, so I stopped the VM. Seems you can’t suspend a VM with a GPU. I also saw when I typed ‘sudo -i’ to switch user to root, it said to ‘docker attach’ to my container. But the container is just like a tty printing out logs, so you can get stuck in the docker, and need to ssh in again.
I think the issue was just that I need to be inside the docker to do things. The VM you log into is just a minimal container running environment. So I think that was my issue. Next time I install gsutil, I’ll run ‘docker exec -it 68ee22bf268f bash’ to get into the docker first.
Ok fired up the VM again. This time I exec’ed into the docker, and gsutil was already installed. gsutil cp -r gs://chicken-drive . is copying the files now. It’s slow, and it says to try with -m, for parallel copying, but I’m just going to let it carry on for now. It’s slow, but I can do some other stuff for now. So far our gcloud bill is $1.80.
Ok, /opt/jupyter/chicken-drive has my data now. But according to /opt/jupyter/.jupyter/jupyter_notebook_config.py, I need to move it under /home/jupyter.
Hmm. No space left on drive. What? 26GB all full. But it wasn’t full a second ago. How can moving files cause this? I guess the mv operation must copy and then delete. Ok, so deleting the new one. Let’s try again, one folder at a time. Oh boy. This is something a bit off about the google process. I didn’t start my container, and if I did, I’d probably map a volume. But the host is sort of read only. Anyway. We’re in. I can see the files in Jupyter Lab.
So now we’re training U-Net binary classification using keras-unet, by karolzak, based on the kz-isbi-chanllenge.ipynb notebook.
But now I’m getting this error when it’s clearly there…
FileNotFoundError: [Errno 2] No such file or directory: '/OID/v6/images/Chicken/train/'
Ok well I can’t work it out but changing it to a path relative to the notebook worked. base_dir = “../../../”
Ok first test round of training, binary classification: chicken, not-chicken. Just 173 image/mask pairs, 10 epochs of 40 steps.
Now let’s try with the training set. 1989 chickens this time. 50/50 split. 30 epochs of 50 steps. Ok second round… hmm, not so good. Pretty much all black.
Ok I’m changing the parameters of the network, fixing some code, and starting again.
I see that the pngs were loading float values, whereas in the example, they were loading ints. I fixed it by adding a m = m.convert(‘L’) to the mask (png) loading code. I think previously, it was training with the float values from 0 to 1, divided by 255, whereas the original example had int values from 0 to 255, divided by 255.
So I’m also resetting the parameters, to make this a larger network, since we’re training in the cloud. 512×512 instead of 256×256. Batch size of 3. Horizontal flip augmentation. 64 filters. 10 epochs of 100 steps. Go go go. Ok, out of memory. Batch size of 1. Still out of memory. Back to test set of 173 chickens. Ok it’s only maxing at 40% RAM now. I’ll let it run.
Ok, honestly I don’t know anymore. What is it even doing? Looks like it’s inversing black and white. That’s not very useful.
Ok before giving up, I’m going to make some changes.
The next day, I’m starting up the VM. Total cost so far, $8.84. The files are all missing, so I’m recopying, though using the gsutil -m cp -R gs://chicken-drive . option, and yes it is a lot faster. Though it slows down.
I think the current setup is maybe failing because we’re using 173 images with one kind of augmentation. Instead of 10 epochs of 100 steps of the same shit, let’s rather swap out the training images.
First problem is that Keras is basically broken, in this regard. I’ve immediately discovered that saving and loading a checkpoint does not save and load the metrics, and so it keeps evaluating against a loss of infinity, instead of what your saved model achieved. Very annoying.
Now, after stopping and restarting the VM, and enabling all cloud APIs, I’m having a new problem. gsutil no longer works. After 4% copied, network throughput drops to 0.0B/s. I tried reconnecting and now get:
Connection via Cloud Identity-Aware Proxy Failed
Code: 4003
Reason: failed to connect to backend
You may be able to connect without using the Cloud Identity-Aware Proxy.
I’ve switched back to ‘Allow default access’. Still getting 4003.
Ok, I’ve deleted the instance. Trying again. Started it up. It’s not installing the docker I asked for, after 22 minutes. Something is wrong. Let’s try again. Stopping VM. I’m ticking the ‘Run as priviliged’ box this time.
Ok now it’s working again. It even started up with the docker ready. I’m trying with the multiprocess copying again, and it slowed down at 55%, but is still going. Phew. Ok.
I changed to using the TF2 SavedModel format. Still restarts the ‘best’ metric. What a piece of shit. I can’t actually believe it. Ok I wrote my own code for finding the best, by saving all weights with the val_loss in the filename, and then loading the best weights for the next epoch. It’s still not perfect, but it’s better than Keras overwriting the best weights every time.
Interestingly, it seems like maybe my training on the Jetson was actually working, because the same weird little vignette-ing is occurring.
Ok we’re up to $20 billing, on gcloud. It’s adding up, but not too badly yet. Nothing seems to be beating a round of training from like 4 hours ago, so to keep things more exploratory, I added a 50/50 chance to pick from the saved weights at random, rather than loading the winner every time.
Something seems to be happening. The vignette is shrinking, but some chicken border action, maybe.
I left it running overnight, and this morning, we’re up to $33 spent, and today, we can’t log into the VM again. Pretty annoying. Of the 3 reasons for ‘Permission denied’, only one makes sense, Your key expired and Compute Engine deleted your ~/.ssh/authorized_keys file.
Same story if I run the gcloud commands: gcloud beta compute ssh –zone “europe-west4-c” “chicken-vm-template-1” –project “gpu-ggr”
So I apparently need to add a new public key to the Metadata section. I just know something is going to go wrong. Yeah, so I did everything I know I’m supposed to do, and it didn’t work. I generated an OpenSSH private/public key pair in PuttyGen, I changed the permissions on the private key so that only I have access, I updated the SSH Keys in the VM instance metadata, and the metadata for good measure. And ssh -i opensshprivate daniel_brownell@34.91.21.245 -v just ends up with Permission denied (publickey).
Ok and then print the public key, and copy paste it to the VM Instance ‘Edit…’ / SSH Keys… and connect with PuTTY with the private key and… nope. Permission denied (publickey).. Ok I need to go through these answers and find one that works. Same error with windows cmd line ssh, except also complains that the openssh key is an invalid format. Try again later.
Fuck you gcloud. Ok I’m stopping and deleting the VM. $43 used so far.
Also, the training through the night didn’t improve on the val_loss score. Something’s fucked.
Ok I’ve started it up again a few days later. I was wondering about the warnings at the beginning of my training that carious CUDA things were not installed. So apparently I need:
So I increased the boot disk to 35GB and called ‘ cos-extensions install gpu’ again, after cd’ing into /mnt/stateful-partition and it worked a bit better. Still has ‘ERROR: Unable to load the kernel module 'nvidia.ko'.‘ in the logs though. But install logs at ./mnt/stateful_partition/var/lib/nvidia/nvidia-installer.log say its ok…
So the error now is ‘Could not load dynamic library ‘libcuda.so.1′; dlerror: libcuda.so.1: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /usr/local/nvidia/lib:/usr/local/nvidia/lib64’
And so we need to modify the docker container run command, something like the example in the instructions.
Ok so our container is… gcr.io/deeplearning-platform-release/tf2-gpu.2-4
According to this stackoverflow answer, this already has everything installed. Ok but the host needs the drivers installed.
tf.config.list_physical_devices('GPU')
[]
So yeah, i think i need to install the cos crap, and restart the container with those volume and device bits.
docker stop klt-chicken-vm-template-1-ursn
docker run \
--volume /var/lib/nvidia/lib64:/usr/local/nvidia/lib64 \
--volume /var/lib/nvidia/bin:/usr/local/nvidia/bin \
--device /dev/nvidia0:/dev/nvidia0 \
--device /dev/nvidia-uvm:/dev/nvidia-uvm \
--device /dev/nvidiactl:/dev/nvidiactl \
gcr.io/deeplearning-platform-release/tf2-gpu.2-4
...
[I 14:54:49.167 LabApp] Jupyter Notebook 6.3.0 is running at:
[I 14:54:49.168 LabApp] http://46fce08b5770:8080/
[I 14:54:49.168 LabApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
^C^C^C^C^C^C^C^C^C^C
Not so good. Ok can’t access it either. -p 8080:8080 fixes that. It didn’t like --gpus all.
“Unable to determine GPU information”. Container optimised shit.
Ok I’m going to delete the VM again. Going to check out these nvidia cloud containers. There’s 21.07-tf2-py3 and NGC stuff.
So I can’t pull the dockers cause there’s no space, and even after attaching a persistent disk, not, because things are stored on the boot disk. Ok but I can tell docker to store stuff on a persistent disk.
/etc/docker/daemon.json:
{
"data-root": "/mnt/x/y/docker_data"
}
root@nvidia-ngc-tensorflow-test-b-1-vm:/mnt/disks/disk# docker run --gpus all --rm -it -p 8080:8080 -p 6006:6006 nvcr.io/nvidia/tensorflow:21.07-tf2-py3
docker: Error response from daemon: OCI runtime create failed: container_linux.go:380: starting container process caused: process_linux.go:545: container init caused: Running hook #0:: error running hook: exit status 1, stdout: , stderr: nvidia-container-cli: initialization error: nvml error: driver not loaded: unknown.
wget https://developer.download.nvidia.com/compute/cuda/11.1.0/local_installers/cuda_11.1.0_455.23.05_linux.run
chmod +x cuda_11.1.0_455.23.05_linux.run
sudo ./cuda_11.1.0_455.23.05_linux.run
or some newer version:
wget https://developer.download.nvidia.com/compute/cuda/11.4.1/local_installers/cuda_11.4.1_470.57.02_linux.run
sudo sh cuda_11.4.1_470.57.02_linux.run
‘boost::filesystem::filesystem_error’
Ok using all the space again. 32GB. Not enough. Fuck this. I’m deleting the VM again. 64GB. SSD persistent disk. Ok installed driver. Running docker…
And…
FFS. Something is compromised. In the time it took to install CUDA and run docker on an Ubuntu VM, an army of Indian hackers managed to delete my root user.
Ok. Maybe it’s time to consider AWS again for GPUs. I think I can officially count GCP GPU as unusable. Learned a few useful things, but overall, yeesh.
I think maybe I’ll just run the training on a cheap non-GPU VM on GCP for now, so that I’m not paying for a GPU that I’m not using.
docker run -d -p 8080:8080 -v /home/daniel_brownell:/home/jupyter gcr.io/deeplearning-platform-release/tf2-cpu.2-4
Ok wow so now with the cpu version, the loss is improving like crazy. It went from 0.28 to 0.24 in 10 epochs (10 minutes or so). That sort of improvement was not happening after like 10 hours on the ‘gpu’.
So yeah, amazing. The code now does a sort of population based training, by picking a random previous set of weights instead of the best weights, half of the time. Overall it slows things down, but should result in a bit more variation in the end.
What finally worked
Ok there’s also an ‘AI platform – notebook’ option. I might try that too.
Ok the instance started up. But it failed to start 4 cron services: nscd, unscd, crond, sshd. CPU use goes to zero. Nothing. Ok so I need to ssh tunnel apparently.
Successfully opened dynamic library libcudart.so.11.0
‘ModelCheckpoint’ object has no attribute ‘_implements_train_batch_hooks’
Ok, needed to change all keras.* etc. to tensorflow.keras.*
Ok fuck me that’s a lot faster than CPU.
Permission denied: ‘weights-0.2439.hdf5’
Ok, let’s sudo it.
Ok there she goes. It’s like 20 times faster maybe. Strangely isn’t doing much better than the CPU though. But I’ll let it run for a bit. It’s only been a minute. I think maybe the CPU doing well was just good luck. Perhaps we trained them too well on the original set of like 173 images, and it was getting good results on those original images.
Ok now it’s been an hour or so, and it’s not beating the CPU. I’ve changed the train / validation set to 50/50 now, and the learning rate is randomly chosen between 0.001 and 0.0003. And I’m upping the epochs to 30. And the filters to 64. batch_size=4, use_batch_norm=True.
We’re down to 23.3 after an hour and a half. 21 now… 3 hours maybe now
Ok 5 hours, lets check:
Holy shit it’s working. That’s great. I’ll leave it running overnight. The overnight results didn’t improve much for some reason.
(TODO: learn about focal loss / dice loss / jaccard distance as possible change to loss function.? less necessary now.)
So it’s cool but it’s 364MB. We need it 1/4 size to run it on the Jetson NX I think.
So, retraining, with filters=32. We’re already down to 0.24 after an hour. Ok I stopped at 0.2104 after a few hours.
So yeah. Good enough for now.
There’s some other things to train, too.
The eggs in simulation: generate views, save images to disk. save segmentation images to disk.
Train the walking again with the gripper.
Eggs in the real world. Use augmentation to place real egg pics in scenes. Possibly use Mask-RCNN/YOLACT code with COCO, instead of continuing in Keras.
The now-working U-net binary chicken segmentation is in Keras, so there will be some tricks required, to run a multi-class segmentation detector, or multiple binary classifiers. Advice for multi-class segmentation is here and the multiple binary classifier advice is here.
When we finally try running it all on a Jetson, we will maybe need to shrink the neural network further. But that can be done last minute. It looks like we can save the h5fs file to TF2’s SavedModel format with model.save(model_fname) and convert to frozen graph, to import into TensorRT, the NVIDIA format. Similar to this. TensorRT shrinks neurons to single bytes, I believe.
I’ve been scouring for existing code to help with developing the gripper in simulation. I was looking for a way to implement ‘eye-in-hand’ visual servoing, and came across a good resource, created for a masters thesis, which shows a ‘robot vision’ window, and he compares depth sensing algorithms. My approach was going to be, essentially, segmentation, in order to detect and localise chickens and eggs, in the field of vision, and then just try get their shape into an X-Y coordinate position, and over a certain size, to initiate interaction.
This one uses an SDF model of a KUKA industrial 6 DOF robot with a two finger gripper, but that has specific rotational movement, that seems maybe different from a simpler robot arm. So it’s maybe a bit overkill, and I might just want to see his camera code.
Miranda’s gripper prototype isn’t a $50k KUKA industrial robot arm. It’s just v.0.1 and got an 11kg/cm MG945, some 5kg/cm MG5010s, and an 1.3kg/cm SG90, and a sucker contraption I found on DFRobot, that can suck eggs.
So, regarding the simulation,this will be on top of the robot, as its head.
So we need an URDF file. Or an SDF file. There’s a couple ways to go with this.
The other resource I’ve found that looks like just what I need, is ur5pybullet
Regarding the ‘visual servoing’, the state of the art appears to be QT-Opt, perhaps. Or maybe RCAN, built on top of it. But we’re not there just yet. Another project specifically uses pybullet. Some extra notes here, from Sergey Levine, and co., associated with most of these projects.
Another good one is Retina-GAN, where they convert both simulation and reality into a canonical format. I’ve also come across Dex-Net before, from UCB.
Everything is very complicated though.
I’ve managed to make an URDF that looks good enough to start with, though. I’ll put everything in a github. We want to put two servos on the ‘head’ for animatronic emotional aesthetics, but there’s a sucker contraption there for the egg, so I think this is good enough for simulation, for now, anyway. I just need to put a camera on its head, put some eggs in the scene, and maybe reward stable contact with the tip. Of course it’s going to be a lot of work.
We also want to add extra leg parts, but I don’t want to use 4 more motors on it.
So I’m playing around with some aluminium and timing belts and pulleys to get 8 leg parts on 4 motors. Something like this, with springs if we can find some.
So, simulator camera vision. I can enable the GUI. Turns out I just need to press ‘g’ to toggle.
Ok I’ve got the visuals now, but I shouldn’t be seeing that shadow
The camera is like 90 degrees off maybe. Could be an issue with the camera setup, or maybe the URDF setup? Ok…
Changing the initial camera vector fixed the view somewhat:
init_camera_vector = (0, 0, 1) # x-axis
Except that we’re looking backwards now.
init_camera_vector = (0, 0, -1) # x-axis
Ok well it’s correct now, but heh, hmm. Might need to translate the camera just a bit higher.
I found a cool free chicken obj file with Creative commons usage. And an egg.
Heh need to resize obj files. Collision physics is fun.
Ok I worked out how to move the camera a bit higher.
pos = list(pos)
pos[2] += 0.3
pos = tuple(pos)
Alright! Getting somewhere.
So, next, I add resized eggs and some chickens for good measure, to the scene.
Then we need to train it to stick its shnoz on the eggs.
Ok… gonna have to train this sucker now.
First, the table is falling from the sky, so I might need to stabilize it first. I also need to randomize the egg location a bit.
And I want to minimize the distance between the gripper attachment and the egg.
The smart way is probably to have it walk until some condition and then grasp, but in the spirit of letting the robot learn things by itself, I will probably ignore heuristics. If I do decide to use heuristics, it will probably be a finite state machine with ‘walking’ mode and ‘gripping’ mode. But we’ll come back to this when it’s necessary. Most of the time there won’t be any eggs in sight. So it will just need to walk around until it is sure there is an egg somewhere in sight.
And the end effector’s position should be something like the original camera position before we moved it up a bit, plus length of the end effector in the URDF (0.618). I ended up doing this:
After checking out the speed of image segmentation on the Raspberry Pi (like one frame every 10 seconds maybe?), and my i3 laptop not being much better, I realised I needed more computing power, at least to train the neural networks. I can probably still ultimately run the neural network on the Pi, but we’ll see.
Looking at computing options, I ultimately went with the $399 NVIDIA Jetson Xavier NX.
Developer Kit Technical Specifications
GPU
NVIDIA Volta™ architecture with 384 NVIDIA® CUDA® cores and 48 Tensor cores
Gigabit Ethernet, M.2 Key E (WiFi/BT included), M.2 Key M (NVMe)
Display
HDMI and DP
USB
4x USB 3.1, USB 2.0 Micro-B
Others
GPIOs, I2C, I2S, SPI, UART
Mechanical
103 mm x 90.5 mm x 34 mm
Also, did you know they made a dystopic reboot retcon of The Jetsons, that 70s retro-futuristic Hanna Barbera cartoon, in comic form? An ice meteor destoyed Earth. They were lucky to have had a place in space to go, working for the Spacely Space Sprockets, incorporated. (YT link)
It took an hour to set up, and was mostly straightforward, though I had to get a ‘clover plug’ cable, and an SD card.
I used Etcher to load the latest 6GB Jetson Developer Kit SD image, and had a keyboard, mouse, and hdmi monitor that worked. So I was able to enter the wifi SSID and password while setting it up.
I learned that one option for headless installation is to use a USB cable from your computer to the micro-USB input of the Jetson. But ultimately this wasn’t necessary. I ran ipconfig on the Jetson, got an ip address, and connected with ssh.
After needing to change the wifi details, I used the usb cable, then connected with:
Coming back to this later, I attempted the same, but with the Jetson Nano, instead of the Jetson Xavier, and it didn’t work. I learned that the Nano doesn’t come with a Wifi adapter.
I think with the Nano, (“B01”) you need a monitor to install. I tried multiple tutorials, ssh’ing 192.168.55.1, I tried using screen to connect to /dev/ttyACC0 at 115200 baud, nope. Looked at the forums, and it’s complicated. I didn’t try the USB UART because my USB-TTL converter’s cable colours are different.
Another method that worked, with the nano, is plugging the ethernet cable from the Nano directly into the wifi router. It then shows up on the router’s network.
Later, when trying to install a D-Link wifi ‘Wireless N Nano USB Adaptor’, ( for the love of God, just get an Edimax – they work out of the box), I connected over ssh with the ethernet cable from the jetson to the router, then downloaded the driver and unzipped and untarred, and then ran the `make` file and `make install` as per the instructions, but had to run export ARCH=arm64 before that, because it was looking in aarch64. Then rebooted. Then
chicken@chicken:~$ sudo nmcli device wifi connect 'ssid' password 'password'
[sudo] password for chicken:
Device 'wlan0' successfully activated with '3a7997e6-c6b1-40f7-bf93-fba5b110282c'.
A lot of research will have to happen again now, though, because NVIDIA has its own software ecosystem. I’ll need a vision solution that is portable to the PI, with the hope that a model or neural net trained on the Jetson will still be able to run on the Raspberry Pi, since it’s 40X cheaper.
The lingo takes some time to get used to, but I believe JetPack is the name for this OS of preinstalled nvidia docs and libraries.
Since last year, an algorithm called… a Transformer… which has just recently created a hell of a chat bot, with GPT-3, and which underlies Google search as BERT (Bidirectional Encoder Representations from Transformers).
And there are hybrid convolutional nets and transformers, eg. DETR, and there are the SOTA from last year, EfficientNet, and then for some instances, or most, YOLOv4 is meant to be the new hot algorithm. It’s bigger than YOLOv3. It’s wait, so it’s more frames per second, and the accuracy (AP) is kinda so/so, at 5% less. I realised YOLOv5, which I had seen, which is a Pytorch implementation, is faster, though it’s technically just some one being a bit of a douchebag and calling his implementation of the author’s peer reviewed, the next version, YOLOv5. So what now?
NVIDIA has this 3d simulator environment in Unreal Engine! Isaac. Something like an API for robots, by NVIDIA. They got this robot working with it, apparently.
It’s actually pretty good. I wonder if this https://developer.nvidia.com/deepstream-sdk is as cool as it sounds. Ah, closed source. Of course. But I can apply to join. Eh maybe.
So, I want to get these chickens into a convolutional neural network, or a transformer and output a pretty picture. I want the colour masks, not the bounding boxes.
I don’t want to get too caught up in proprietary NVIDIA specific API, even if they have an Unreal Engine simulator. But it might be worth checking out. GStreamer is an open source port of it, so maybe back on the menu.
But it’s a whole integrated thing. “The DeepStream SDK can be used to build end-to-end AI-powered applications to analyze video and sensor data. Some popular use cases are: retail analytics, parking management, managing logistics, robotics, optical inspection and managing operations.”
Nice. DeepStream supports several popular networks out of the box such as YOLO, FasterRCNN, SSD, RetinaNet and MaskRCNN.
I get the sense that Gems in the DeepStream world of Isaac, are like, ROS nodes, offering services on a port. ORB is a Gem. Ultimately, a prediction, or reconstruction in 3d, of the shape of objects in the world, would be ideal. I’m only doing the colour map stuff because the colours are nice, and it looks more impressive. But ultimately I will need to pick the best tool for the job.
NVIDIA also has DIGITS, Deep Learning GPU Training System (DIGITS) … puts the power of deep learning into the hands of engineers and data scientists. DIGITS can be used to rapidly train the highly accurate deep neural network (DNNs) for image classification, segmentation and object detection tasks.
So as you can see, there’s more to find out. But ultimately I will probably have to repeat the task of getting labelled data into folders, and having the labels in the right format. Then generating the TFRecords, or doing whatever you do in PyTorch, I’m still biased to the TensorFlow ODI 2 implementation, because Google’s got the best dataset of chickens.
One of the main decisions is how to train the Vision. We have an NVIDIA Jetson NX now, which can work on training in the background.
We will try Tensorflow 2 first, and if training is slow, we can try TensorFlow with TensorRT (TF-TRT).
But we’re starting from scratch. As the title suggests, we’re going to try get U-Net working. A neural network shaped like a U, for instance segmentation.
So, dev environment with virtual environments and pip? or Docker?
Let’s try Docker first. Some instructions here and here…
I prefer tagged versions to ‘latest’ because they’re probably more stable.
Working from Jupyter Notebook will be a good way to preserve the code, and if we can use Docker, let’s do that, because containers are easier to deal with, usually, than virtual python environments on a host. We’ll leave this for now because we need to prepare the data.
OIDv6
In the meantime, I need to redo the OID (Open Images) download with bounding boxes or segmentation mask info. Let’s go straight for segmentation, using the method we tried before.
Need dev setup basics. give me some curl and some pip3.
and now feed this into a downloader program. We can use the suggested downloader.py script. but I liked this bash function method. The downloader.py needs the files prefixed with the directory, which is a bit annoying. In Linux, you’d need to use sed to put the directory names in front of every line.
Now I need the PNG files that are the masks for these images.
It seems like these are the 16 zip files.
wget https://storage.googleapis.com/openimages/v5/train-masks/train-masks-0.zip through 16. Oh but it goes 0-9, then A-F.
So, ok how to automate this? bash or perl or python? ok..
for i in {0..9}; do wget https://storage.googleapis.com/openimages/v5/train-masks/train-masks-$i.zip; done
well good enough automation for now. if I used hex maybe I can loop 1..F in bash. Let’s compromise. I could have copy pasted in this time.
for i in {'a','b','c','d','e','f'}; do wget https://storage.googleapis.com/openimages/v5/train-masks/train-masks-$i.zip; done
They’re 262MB each file.
unzip *
2686684 files… yikes
ok i need to find the PNG masks associated with the JPG images. I can work this out but I am flying blind. Chicken is /m/09b5t –
ls -l | grep 09b5t
ls -l | grep 09b5t | wc -l
shows 2237 masks for Chickens. But we only have 1324 images of Chickens.
Ok I need to see pics on the jetson. Ultimately an RDP (remote desktop protocol would be best?). VNC server is an old code but it checks out. Followed these instructions. and connected to 192.168.101.109:5901
Nope. It’s comically small at 640×480.
VNC listening on port 5901
Ok but yeah I guess I just wanted to see the pictures. But this isn’t really necessary yet, or practical over VNC. I want to verify that the PNG mask corresponds to the JPG image contents. I’ll probably use a Jupyter Notebook ultimately. (I do end up using Jupyter Lab.)
We’re configuring Tensorflow 2 or PyTorch to train some convolutional network with this segmentation data.
It’s got the mappings, and some extra factoids about where the Google data entry annotator people clicked with their wand selection tool, and a “Predicted IoU”, which is a big topic. We should hopefully only need the image to segmentation file mapping.
MaskPath: name of the corresponding mask image.
ImageID: the image this mask lives in.
LabelName: the MID of the object class this mask belongs to.
BoxID: an identifier for the box within the image.
BoxXMin, BoxXMax, BoxYMin, BoxYMax: coordinates of the box linked to the mask, in normalized image coordinates. Note that this is not the bounding box of the mask, but the starting box from which the mask was annotated. These coordinates can be used to relate the mask data with the boxes data.
PredictedIoU: if present, indicates a predicted IoU value with respect to ground-truth. This quality estimate is machine-generated based on human annotator behaviour. See [3] for details.
Clicks: if present, indicates the human annotator clicks, which provided guidance during the annotation process we carried out (See [3] for details). This field is encoded using the following format: X1 Y1 T1;X2 Y2 T2;X3 Y3 T3;.... Xi Yi are the coordinates of the click in normalized image coordinates. Ti is the click type, value 0 indicates the annotator marks the point as background, value 1 as part of the object instance (foreground). These clicks can be interesting for researchers in the field of interactive segmentation. They are not necessary for users interested in the final masks only.
Ok the masks folder is too big though. Let’s just do Chicken, ok? So we’ll delete any PNGs that don’t have m09b5t in their filename. And delete these zip files.
#!/bin/bash
for i in 1 2 3 4 5 6 7 8 9 a b c d e f
do
eval "unzip train-masks-$i.zip -d masks/"
cd masks
find ! -name 'm09b5png' -delete
mv /home/chicken/OID/v6/masks/* /home/chicken/OID/v6/Chicken
cd ..
done
I need to display the information somehow. Jupyter Lab (Notebooks) are probably the best way to display code, and run it interactively.
chicken@jetson:~$ jupyter notebook --generate-config
Writing default config to: /home/chicken/.jupyter/jupyter_notebook_config.py
chicken@jetson:~$ jupyter-lab
Ok so I wasn’t sure why I couldn’t connect to the server on the Jetson, but I’m able to run it at http://localhost:8888/ through an SSH tunnel.
I’m not sure what the difference between Lab and Notebook is, exactly, yet, either. But I think Notebook is a subset of Lab.
Ok so I’m trying to match JPGs and PNGs. Some interesting data, with multiple masks for some images, and no masks for some images.
I set up SAMBA to copy files over and investigate.
I see. The disturbing part is that no images in my test and validation folders matched any masks. But all of the train images had a match…
OH. train, validation and test ALL have their own 16 zip files of masks.
Good thing I automated that… ok so same thing, but changing ‘train’ to the ‘validation’ and ‘test’.
I did a programmatic test on the directories to see if any images were missing a mask:
for fname in os.listdir(test_images_dir):
if len(glob.glob(test_masks_dir + "*" + fname[:-4] + "*")) == 0: print(fname)
It’s looking better. Still some missing, but good enough now. Missing 6 validation masks, and 12 test masks. All training images have at least one mask
Number of Train images: 1122
Number of Train masks: 2237
Number of validation images: 44
Number of validation masks: 59
02a0f2858f27a7ba.jpg
01463f5494340d3d.jpg
00e71a70a2f669ff.jpg
05887f57bc232041.jpg
0d3da02e79f84dde.jpg
0ed7092c41c81d14.jpg
Number of test images: 154
Number of test masks: 186
0e9be8b09f71f909.jpg
0913fbf6fa5c190e.jpg
0f8a38312499d209.jpg
0650a130d7f707b5.jpg
0a8a5aa471796fd5.jpg
0cc4722ca906f86c.jpg
04423d3f6f5b8e74.jpg
03bc7fbc956b3a9a.jpg
07621394c8ad0b47.jpg
000411001ff7dd4f.jpg
0e5ecc56e464dcb8.jpg
05600e8a393e3c3a.jpg
I’ll move these ones out of the folder.
mkdir ~/backup
cd /home/chicken/OID/v6/images/Chicken/validation/
mv 02a0f2858f27a7ba.jpg ~/backup
mv 01463f5494340d3d.jpg ~/backup
mv 00e71a70a2f669ff.jpg ~/backup
mv 05887f57bc232041.jpg ~/backup
mv 0d3da02e79f84dde.jpg ~/backup
mv 0ed7092c41c81d14.jpg ~/backup
cd /home/chicken/OID/v6/images/Chicken/test/
mv 0e9be8b09f71f909.jpg ~/backup
mv 0913fbf6fa5c190e.jpg ~/backup
mv 0f8a38312499d209.jpg ~/backup
mv 0650a130d7f707b5.jpg ~/backup
mv 0a8a5aa471796fd5.jpg ~/backup
mv 0cc4722ca906f86c.jpg ~/backup
mv 04423d3f6f5b8e74.jpg ~/backup
mv 03bc7fbc956b3a9a.jpg ~/backup
mv 07621394c8ad0b47.jpg ~/backup
mv 000411001ff7dd4f.jpg ~/backup
mv 0e5ecc56e464dcb8.jpg ~/backup
mv 05600e8a393e3c3a.jpg ~/backup
Ok and now all the images have masks!
Number of Train images: 1122
Number of Train masks: 2237
Number of validation images: 38
Number of validation masks: 59
Number of test images: 142
Number of test masks: 186
Momentous. Looking at the nicolas windt article, there might be some dead links. So let’s delete those images too.
find -size 0 -delete
Number of Train images: 982
Number of Train masks: 2237
Number of validation images: 32
Number of validation masks: 59
Number of test images: 130
Number of test masks: 186
Oof, still good. Let’s load a picture in Jupyter. Ok tensorflow has a loadimage function.
No module named 'tensorflow'
Right. We tried installing it with Docker. How will that even work? Eish, gotta read up on this.
Back to Tensorflow.
Ok I already downloaded an NVIDIA-friendly tensorflow 3 weeks ago. Well, things move slowly, but all incremental gains move things forward. With experience you learn ways not to do things.
chicken@jetson:~/OID/v6/images$ sudo docker images REPOSITORY TAG IMAGE ID CREATED SIZE tensorflow/tensorflow 2.4.1-gpu-jupyter 64d8717296f8 3 weeks ago 5.71GB dustynv/jetson-inference r32.5.0 ccc2a5f19dad 3 weeks ago 2.89GB nvidia/cuda 11.0-base 2ec708416bb8 5 months ago 122MB
Ok the TF2 instructions say…
Start a GPU container, using the Python interpreter.
Run a Jupyter notebook server with your own notebook directory (assumed here to be ~/notebooks). To use it, navigate to localhost:8888 in your browser. So…
$ docker run -it --rm -v ~/notebooks:/tf/notebooks -p 8888:8888 tensorflow/tensorflow:2.4.1-gpu-jupyter
Error...
standard_init_linux.go:211: exec user process caused "exec format error"
And pip?
chicken@jetson:~$ pip3 install tensorflow Defaulting to user installation because normal site-packages is not writeable ERROR: Could not find a version that satisfies the requirement tensorflow ERROR: No matching distribution found for tensorflow
Great. Sanity check…
docker run -it --rm tensorflow/tensorflow bash
standard_init_linux.go:211: exec user process caused "exec format error"
Ok. Right, Jetson is aarch64, not x86-64… so google is suggesting Archiconda. This is too much for now. What’s wrong with pip? Python 3.6.9 is supposed to work with TF2.4.1 https://pypi.org/project/tensorflow/ hmm i guess there’s just no aarch64 version of TF2 precompiled.
So… one option is switch to PyTorch. Other option is try archiconda. I’m going to try this: https://ngc.nvidia.com/catalog/containers/nvidia:l4t-ml
“The Machine learning container contains TensorFlow, PyTorch, JupyterLab, and other popular ML and data science frameworks such as scikit-learn, scipy, and Pandas pre-installed in a Python 3.6 environment. Get started on your AI journey quickly on Jetson with everything pre-installed in this container.”
ok now we’re cooking. (No chickens were cooked during the making of this.)
So now I’m back on track, at like step 0.
I’m working off the Keras U-Net code now, from https://keras.io/examples/vision/oxford_pets_image_segmentation/ because it’s one of the simplest CNNs out there, from 2015. I’ve also opened up another implementation because it has more useful examples for training.
Note though that due to U-Net’s simplicity, it is often used for medical computer vision applications, since there’s not so much deep learning magic going on. You can quite easily imagine the latent representation dwelling somehow, at the bottom of the U shaped neural network. It should give us something interesting.
Let’s find the latent representation of a chicken.
We need to correlate the images and masks. We can glob by file name. Probably good as anything. But should probably put it in arrays of arrays or something. One image, many masks. So like a map from an image filename, to a list of mask filenames. As python calls maps, ‘dictionaries’.
Ok amazing, that works. I can see image and mask, and they correspond.
At some point I need to transform these. Make them all 256×256 pixels or something like that. Hmm.
OK, I got the training running. I got the Jetson like a month ago now, probably.
Had to reduce the batch size and epoch size, to get rid of an Out of Memory error. Then had a sort of browser freeze.
I should really run a script like this, instead:
nohup train.py &
but instead i’m hoping i can run it in Jupyter and it just follows the execution, and doesn’t freeze up. Maybe if I remove some debugging text…
But the loss function wasn’t going anywhere, even after 50 epochs, overnight. The mask prediction is just all black.
And I need to restart the Docker to open the tensorboard port
For Docker users: In case you are running a Docker image of Jupyter Notebook server using TensorFlow’s nightly, it is necessary to expose not only the notebook’s port, but the TensorBoard’s port. Thus, run the container with the following command:
docker run -it -p 8888:8888 -p 6006:6006 \
tensorflow/tensorflow:nightly-py3-jupyter
or in my case,
sudo docker run -it -p 8888:8888 -p 6006:6006 --rm --runtime nvidia --network host -v /home/chicken/OID:/opt/OID -v /home/chicken/notebooks:/opt/notebooks nvcr.io/nvidia/l4t-ml:r32.5.0-py3
hmm the python 'magic' is not working
Ok so I ran tensorboard inside the docker terminal, instead of in the notebook. (You can do that by checking the container ID of 'docker ps' and calling 'docker exec -it <ID> bash')
python3 -m tensorboard.main --logdir=/opt/notebooks/logs
from tensorboard import notebook
import datetime
#%load_ext tensorboard
%reload_ext tensorboard
%tensorboard --logdir /opt/notebooks/logs
notebook.list()
notebook.display(port=6006, height=1000)
ok yeah so my ML model didn't learn shit.
Also apparently they don't have tensorflow 2 in this nvidia ML docker container.
root@jetson:/opt/notebooks/logs# pip3 show tensorflow
Name: tensorflow
Version: 1.15.4+nv20.11
So how to debug? The images are converted to an n-dimensional array.
Got array with shape: (4, 256, 256, 1)
Ok things are going weird now, almost as I notice the TF version. It must be getting late.
Next day: Ok Nvidia has a TF2 docker, and it shares about half the layers with the other docker, so that’s cool: nvcr.io/nvidia/l4t-tensorflow:r32.5.0-tf2.3-py3
But it doesn’t have jupyter installed. Maybe I can copy the relevant bits from the Dockerfile. I’ve tried installing Jupyter and committing the docker, but “Failed building wheel for cffi”, some aarch64 issue.
RUN apt-get update && apt-get install -y libffi6 libffi-dev
Hard to find the nvidia docker files, and they only have l4t-base available.
finally. So, back to tensorflow, and running U-Net!
So, maybe I see a problem with the semantic segmentation, possibly, which is related to chickens being a category among other things, rather than a binary chickeness and non-chickenness :
SparseCategoricalCrossentropy class
” Use this crossentropy metric when there are two or more label classes. “
I only have one class. Chicken. So that won’t work. I need an egg dataset. Luckily this implementation has an example of an eye, and the veins, and that is why we want the U-Net, for the egg anomaly detection.
The problem’s symptom is that nothing is being learned during training. So maybe I’m using the wrong loss function.
I need to review instance segmentation “options”.
The loss function is currently measuring “the crossentropy metric between the labels and predictions.”
The reason I want instance segmentation is to differentiate between chickens, where possible. Panoptic segmentation actually makes the most sense for this project.
Panoptic segmentation uses a semantic network and an instance network, and uses them both, to deliver something like (“cat”,0), (“cat”,1), (“cat”,3)
…
COCO Panoptic API looks great, but it seems to need json to describe all of the PNG images. Bounding boxes seems unnecessary but COCO needs bounding boxes data.
We’ll start a new post on Panoptic Segmentation using COCO, and get back to Tensorflow 2 for U-Net, for semantic segmentation, when training on lit up eggs for in ovo sexing.
…
Update after a hiatus: I see a recent nnU-Net advancement… It’s a meta modelling process evolution thing. “self-configuring” for biomedical imaging. Hmm. Very interesting.
We’re not there yet. We just want to get a basic U-Net working.
I see too, Perceptilabs from W&B is released and they have some beautiful screenshots too, though not available on pip3 yet for aarch64. So it’s not an option at the moment.
So, for reminder, in this post, we’re trying to get basic U-Net segmentation working. Here’s a good explanation of it.
…
“Back to U-net”
I’ve found another implementation of U-Net that seems a bit more plug and play. There is also a useful note here regarding U-Net and the number of classes. https://github.com/karolzak/keras-unet/issues/3
One of their notebooks looks like a promising notebook, the kz-isbi-challenge.py, and I rigged it to run on my data, and I get OOM. Out of Memory. But this is jupyter lab. Let’s not train it in jupyter lab. Seems like a bad idea. Like a common problem that there’s probably a solution to, but where the solution is probably, ‘use python, dumbass’ So, converted to py, and edited. Had to take out all the plotting code. Pity. But same problem.
I found a jetson-stats https://github.com/rbonghi/jetson_stats jtop program and though it only showed 6.2GB/8GB of RAM the whole time, (I wasn’t even using up all the RAM?), it did remind me that i’m in a Docker, and maybe I’m not using swap space, and that 8GB is probably not enough RAM for a conv net. The U-Net had 31 million params.
Trainable params: 31,030,593
ResourceExhaustedError: OOM when allocating tensor with shape[32,128,256,256] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[node functional_1/concatenate_3/concat (defined at <ipython-input-26-51303ee95255>:7) ]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
[Op:__inference_test_function_3292]
Hmm. Well, about the docker swap space, docker will use the resources it can, on the host, which is gonna be just a bit less than whatever the host can handle. So when it crashed, It appears to me that it’s trying to load gpu memory, and only has 400MB or so.
So that was the advice from the repo author, that you should check your threads to see if they’ve allocated memory already, leaving none for other processes. (top or ps -ef) to see processes running.
After killing jupyter, I left it training overnight, on 300 training images and masks, from our chicken dataset, and it ran out of memory. But it looks like it finished training before it crapped out, and this time, the Out of Memory (OOM) error had some bigger numbers.
2021-06-08 08:15:21.038084: I tensorflow/core/common_runtime/bfc_allocator.cc:1040] total_region_allocated_bytes_: 1400856576 memory_limit_: 1400856576 available bytes: 0 curr_region_allocation_bytes_: 2801713152
2021-06-08 08:15:21.038151: I tensorflow/core/common_runtime/bfc_allocator.cc:1046] Stats:
Limit: 1400856576
InUse: 616462592
MaxInUse: 1400851712
NumAllocs: 37528
MaxAllocSize: 1280887296
Reserved: 0
PeakReserved: 0
LargestFreeBlock: 0
And you can see the loss was decreasing. That's cool.
So that third, ghostly column, is the one we're watching. I think it's just not very good yet. But maybe I don't understand what it's doing, exactly, either. I am expecting that when I'm done here, it should be able to make the mask, from just the image.
So that was training with the second one, last night. I will continue with it for now. Jaccard distance is, union minus intersection, over union. Sounds good to me. Optimising, using Stochastic Gradient Descent, with some hyperparameters.
Let’s leave it training again. I’m also upping the ratio between training and validation data, from 50/50 to 80/20. why not.
Also, the code we had before, for the first U-Net attempt, in the ‘Chicken Vision.py’ notebook, seemed more memory efficient, because it was lazy loading the images. But maybe much of a muchness. We’ll see, perhaps.
So training isn’t working anymore, it seems.
W tensorflow/core/kernels/gpu_utils.cc:49]
Failed to allocate memory for convolution redzone checking; skipping this check. This is benign and only means that we won't check cudnn for out-of-bounds reads and writes. This message will only be printed once.
Ok we might need a cloud gpu. Jetson NX not cutting it.
From a while later, after cloud gpus, it is worth noting that there is a weed detection U-Net using two different loss functions, Dice loss, and ‘Focal Tversky loss’, and only has a 19,667 parameter NN. That’s orders of magnitude smaller, so I might want to come back and see how.
The architecture of the neural network has two pyramids, one for semantics (classes), and one to count the instances
After much circular investigation, i arrived at the notion that transfer learning from a pre-trained network, with the ‘fine tuning’ referring to adding a new class, is the way to go.
But we’re still suffering from not having found an example using PNG mask files. I can convert to COCO, and that might be what I do yet, because, like the dataset had their own Panoptic segmentation challenge and format. https://cocodataset.org/#panoptic-eval They seem to be winning this race. We’ll do COCO.
It will mostly involve writing or exporting info into json format, and following some terse, ambiguous instructions.
Another thing is that COCO wants bounding boxes too. So this will be an exercise in config generation to satisfy the COCO format requirements. I have the data from Open images, but COCO looks like the biggest game in town.
Then for algorithm, there’s numerous Pytorch libraries, especially a very relevant one, YOLACT Edge, using a ‘Darknet’ architecture, which is an old “Open Source Neural Networks in C”
Hmm. It’s more instance segmentation than panoptic, but looks like a good compromise, to aim for.
The eager_few_shot_od_training_tflite.ipynb notebook also looks like a winner for showing how to add a new Duck class to a MobileNet architecture. YOLACT Edge has a MobileNet model available too.
I am sitting with a thousand or so JPGs of chickens with corresponding PNG masks, sorted into train/val/test datasets. I was hoping for the Keras UNet segmentation demo to work because I initially thought UNet will be ideal for the egg light camera, but now I’m back to the FAIR detectron2 woods, to find a panoptic segmentation solution.
Let’s try the YOLACT Edge one, because it’s based on YOLO, (You only look once), a single shot object detector algorithm, but which is also more commonly known for ‘You only live once’, an affirmation of often reckless behaviour. YOLACT stands for You Only Look At CoefficienTs. In this case it looks like the state of the art, and it’s been used on the Jetson before, which is promising. At 30 frames per second on the Jetson AGX, we’ll probably be getting 20 or so on the Jetson NX. Since that’s using Torch to TensorRT to speed it up, it seems like we should try it. I was initially averse to using NVIDIA specific software, but we should make the most of this hardware (if we can)
It’s not really panoptic segmentation. But it’s looking Good Enough™ like what we need, rather than what we thought we wanted.
For the panoptic task, each annotation struct is a per-image annotation rather than a per-object annotation. Each per-image annotation has two parts: (1) a PNG that stores the class-agnostic image segmentation and (2) a JSON struct that stores the semantic information for each image segment. In more detail:
To match an annotation with an image, use the image_id field (that is annotation.image_id==image.id).
For each annotation, per-pixel segment ids are stored as a single PNG at annotation.file_name. The PNGs are in a folder with the same name as the JSON, i.e., annotations/name/ for annotations/name.json. Each segment (whether it’s a stuff or thing segment) is assigned a unique id. Unlabeled pixels (void) are assigned a value of 0. Note that when you load the PNG as an RGB image, you will need to compute the ids via ids=R+G*256+B*256^2.
For each annotation, per-segment info is stored in annotation.segments_info. segment_info.id stores the unique id of the segment and is used to retrieve the corresponding mask from the PNG (ids==segment_info.id). category_id gives the semantic category and iscrowd indicates the segment encompasses a group of objects (relevant for thing categories only). The bbox and area fields provide additional info about the segment.
The COCO panoptic task has the same thing categories as the detection task, whereas the stuff categories differ from those in the stuff task (for details see the panoptic evaluation page). Finally, each category struct has two additional fields: isthing that distinguishes stuff and thing categories and color that is useful for consistent visualization.
Right, so, if anything, we want to transfer learn from a trained neural network. There’s some interesting discussion about implementing your own transfer learning of a coco dataset, in keras-retinanet here, but we’re looking at using Yolact Edge, based on pytorch, so let’s not get distracted. We need to create the COCO dataset. I’ve put this off for so long.
We need the COCO categories that are already trained, and I see there is the 2018 api https://github.com/cocodataset/panopticapi which has the Panoptic challenge coco categories (panoptic_coco_categories.json) and ah ha this is what I have been searching for.
Ok hold on though. Let’s try get some visualisation working, before anything else. This looks like the ticket. But it is a python file, and running matplotlib, so ideally we’d transform this to a Jupyter Notebook. Ok, just New Notebook, copy paste. Run.
ModuleNotFoundError: No module named 'skimage'
[Big Detour and to the rescue, Datamachines]
Ok we can install it with !pip3 install scikit-image ? No, that fails… what did I do, right, I need to ssh into the Jetson,
Then find the docker ID, and docker exec -it 519ed46162ae bash into it, and goddamnit what, UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xc3 in position 4029: ordinal not in range(128)
Ok so someone’s already had this happen, and it’s because the locale preferred encoding, needs to be UTF-8. But it’s some obscrure ANSI.
As per the latest comment, (only 3 weeks ago, others were on the trail of similar tasks!), mmartial is pointing to datamachines, which has some Dockerfiles for building OpenCV and Tensorflow, and YOLOv4.
Ok, let’s try what the instructions suggest:
“make tensorflow_opencv to build all the tensorflow_opencv container images”
I’ll try the CuDNN version next if this doesn’t work…
Ok…we’re on step 16 of 42… Ooh Python 3.8, that’s an upgrade. Build those wheels, pip3! Doh, Step 24 of 42.
bazel: Exec format error
The command returned a non-zero code: 2
*Whomp whomp* sound
ok let’s try
make cudnn_tensorflow_opencv, no…
I asked on the Issues, and they noticed those are the amd64 builds, not the aarch64 build. I could use their DockerHub pre-build for now.
so after a detour, i am using this Dockerfile successfully to run Jupyter on the NX. We got stuck because skimage was difficult to install, and now we’re back on track, annotating the COCO, and so on.
Right. Panoptic API, we wanted to run visualize.py, first, so we could check progress. But it needed skimage installed. Haha. Ok, one week later… let’s try see the example.
Phew, ok. Getting back on track. So now we want to train it on the chickens.
So, COCO.
“Back to COCO”
As someone teaching myself about this, I know what I ideally want is to transfer learn from a trained network. But it isn’t obvious how. I apparently need to chop off the last layer of a trained network, freeze most of the network, and then retrain the last bit.
and then resume training from yolact_im700_54_80000.pth: python train.py --config=<your_config> --resume=weights/yolact_im700_54_800000.pth --start_iter=0
When there are size mismatches between tensors, Pytorch will spit out an error message but also keep on loading the rest of the tensors anyway. So here we just attempt to load a checkpoint with the wrong number of classes, eat the errors the Pytorch complains about, and then start training from iteration 0 with just those couple of tensors being untrained. You should see only the C (class) and S (semantic segmentation) losses reset.
You probably also want to modify the learning rate, decay schedule, and number of iterations in your config to account for fine-tuning.